反馈-爬虫的时候搭配xpath插件验证很好用
功能建议
·
1235 次浏览
张自信
创建于 2021-12-11 10:19
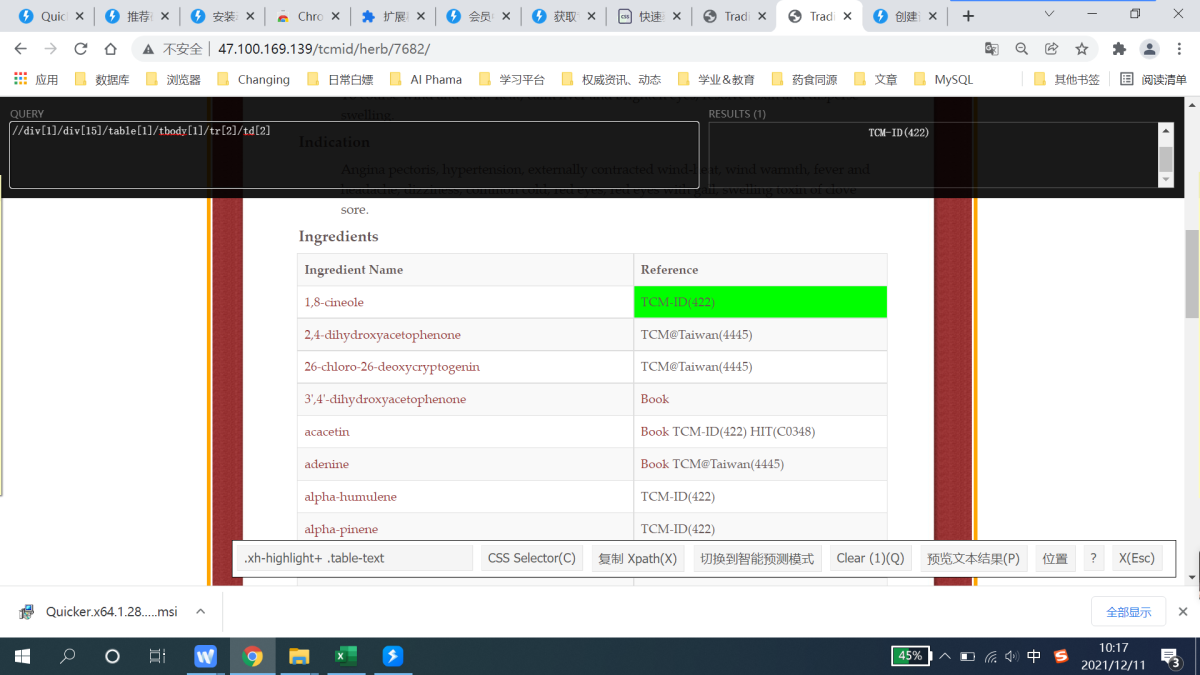
爬虫的时候搭配xpath插件验证很好用,但就是前面路径太长可能识别不了,但保留后面的部分就行,下面是原来识别出来的xpath路径,我在xpath插件中输入的部分删掉了前面挺长一部分
.//*[contains(concat(" ",normalize-space(@class)," ")," xh-highlight ")]备选分隔标记//*[contains(concat( " ", @class, " " ), concat( " ", "xh-highlight", " " ))]备选分隔标记//*[@id="content"]/div[1]/div[1]/div[15]/table[1]/tbody[1]/tr[2]/td[2]
回复
请绑定手机号后发表评论
回复内容
暂无回复

 京公网安备 11010502053266号
京公网安备 11010502053266号