通常情况下,一个中文文字和英文字母,都算作1个字符。
如果有特殊情况需要区分统计,可以使用表达式:
$= Encoding.Default.GetByteCount({文本变量})
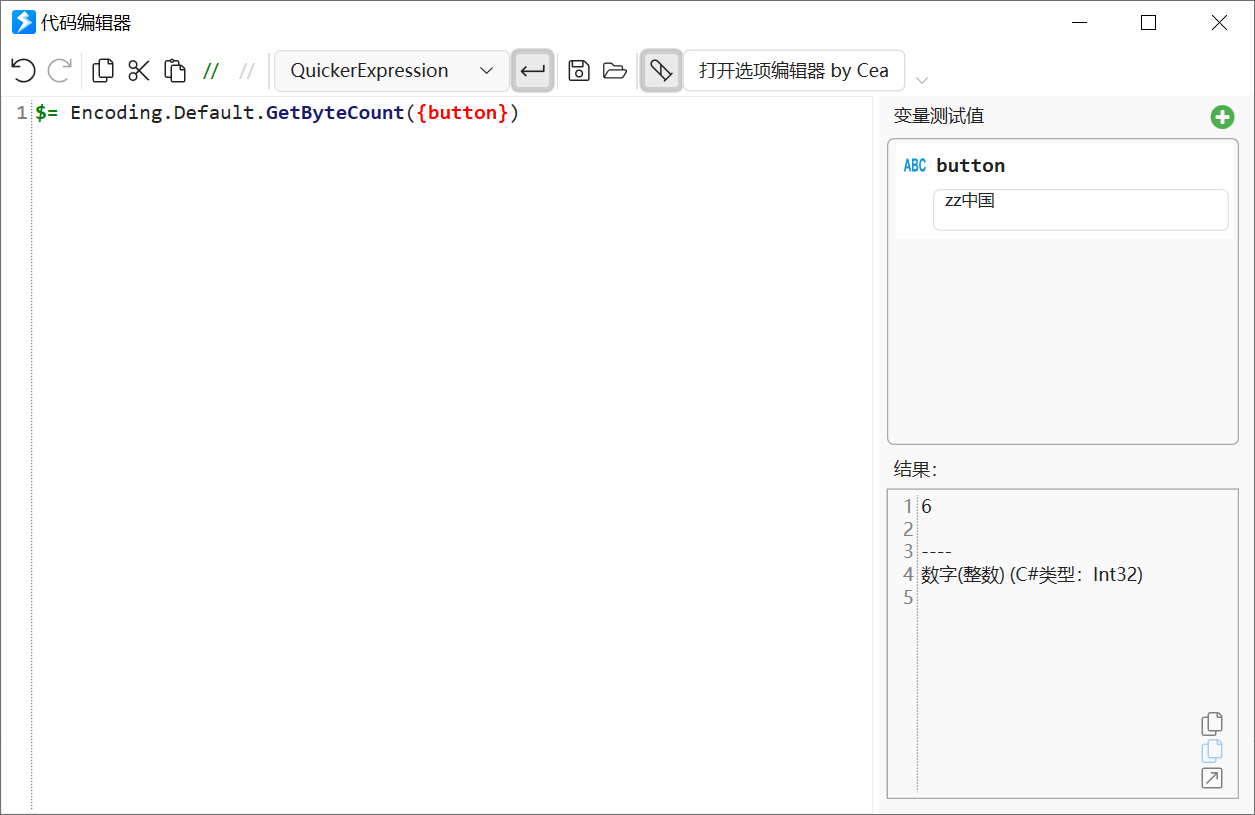
这段代码的意思是获取系统默认编码(对简体中文就是GB2312编码)对文本内容编码后的长度。
GB2312编码每个英文字母占1个字节,中文占2个字节,正好和需要计算的长度一致。
通常情况下,一个中文文字和英文字母,都算作1个字符。
如果有特殊情况需要区分统计,可以使用表达式:
$= Encoding.Default.GetByteCount({文本变量})
这段代码的意思是获取系统默认编码(对简体中文就是GB2312编码)对文本内容编码后的长度。
GB2312编码每个英文字母占1个字节,中文占2个字节,正好和需要计算的长度一致。

 京公网安备 11010502053266号
京公网安备 11010502053266号