怎么在不打开网页的情况下获取想要的数据
湘喑
创建于 2022-04-14 14:35
首先说明,本人编程方面是小白,前端知识基本为0
场景:我需要在一个网站进行搜索,用http://www.yiparts.com/search?type=number&keyword=加上一个编码就是搜索的页面,如编码97VB3395BA的搜索页面为http://www.yiparts.com/search?type=number&keyword=97VB3395BA,打开网址后页面如图:
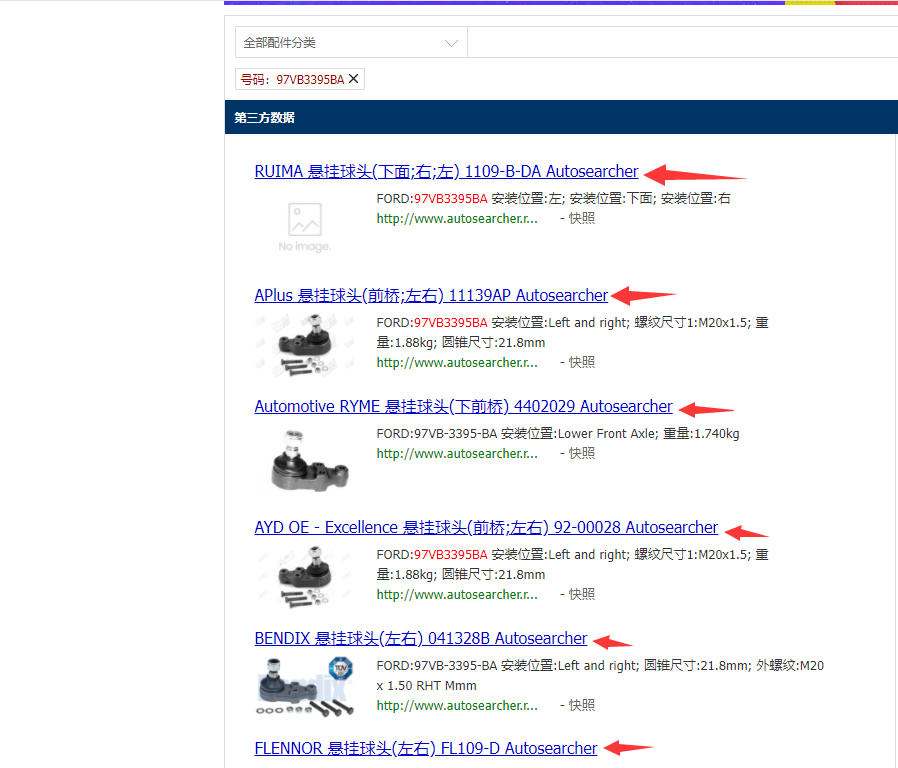
然后我需要进入每个链接里面,获取到OEM编码,如下图中的编码
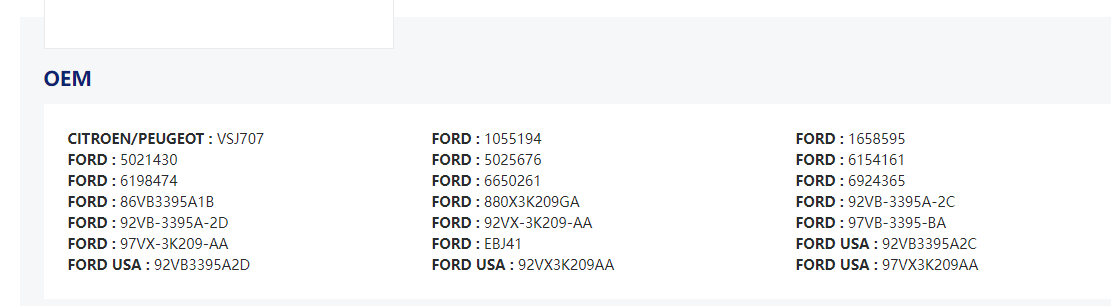
本来的想法是通过HTTP请求模块获取网页原代码,然后再获取数据,但搜索页面的源代码里查找不到搜索结果的链接,通过审查元素才能查出来。还有就是获取所有编码应该怎么做呢,我百度了一下可以通过JS脚本document.getElementsByClassName获取,但不知道怎么用QUIKER现有的模块去比较快捷的实现?
现在的需求是:能不能根据一个编码,不用打开网页,即可获取所有想要的结果编码

 京公网安备 11010502053266号
京公网安备 11010502053266号