如何获取指定网页的响应标头
最近在学习JavaScript爬虫方面的知识,本人小白没系统学过,写代码全靠GPT,可能方向有跑偏,熟悉的大佬随便聊两句也行。
目的:获取指定网页的「响应标头」。
如获取网址https://getquicker.net/的响应标头
(只是举个例子,群里Zryan大佬有提过「http模块请求」获取的方案,实测不需登陆的可以行!因为我实际应用需要登陆网站,所以可能此方案不太适合,用浏览器控制--后台运行代码可以绕过登陆环节进行获取)
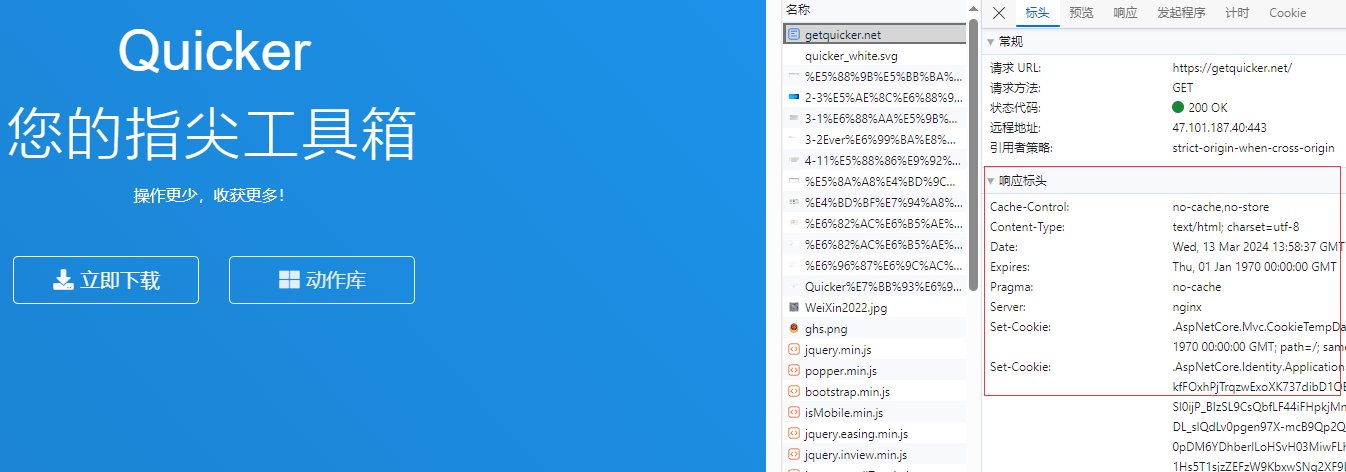
用浏览器控制模块--后台运行代码,下面是gpt写的代码,发现不起作用,特来求助,熟悉的大佬指点一下
const url = 'https://getquicker.net/';
fetch(url, {
method: 'HEAD'
})
.then(response => {
const headers = response.headers.entries();
const headersJson = {};
for (const [key, value] of headers) {
headersJson[key] = value;
}
console.log(headersJson);
})
.catch(error => {
console.error('Error:', error);
});
sendReplyToQuicker(true, "ok", headersJson, qk_msg_serial);
下面是动作链接:https://getquicker.net/Sharedaction?code=135a9cd4-231e-4bb3-a429-08dc435c8f91
这里提别感谢一下zetalpha巨佬的帮助:https://getquicker.net/Sharedaction?code=58fe6922-0c3e-406b-a42b-08dc435c8f91
zetalpha巨佬的方案不用登陆的网址的已经解决;需要登陆的网址目前获取为空,或者获取不到全部内容。
4圈-北京 大佬的方案:https://getquicker.net/Sharedaction?code=f6a0ae5e-40e2-4432-a42d-08dc435c8f91
感谢zetalpha大佬多次耐心出手:https://getquicker.net/Sharedaction?code=58fe6922-0c3e-406b-a42b-08dc435c8f91(标签url 不可能有重定向 因为已经跳转了)
回复内容
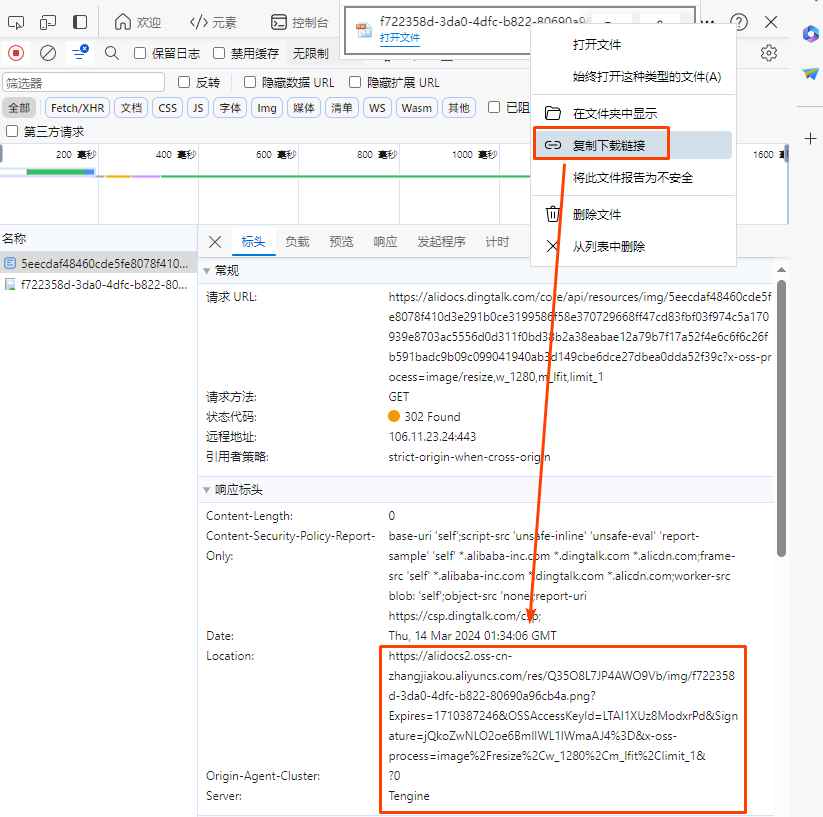
这个是下载的url:https://alidocs.dingtalk.com/core/api/resources/img/5eecdaf48460cde5fe8078f410d3e291b0ce3199586f58e370729668ff47cd83fbf03f974c5a170939e8703ac5556d0d311f0bd38b2a38eabae12a79b7f17a52f4e6c6f6c26fb591badc9b09c099041940ab3d149cbe6dce27dbea0dda52f39c?x-oss-process=image/resize,w_1280,m_lfit,limit_1
实际下载的URL是:https://alidocs2.oss-cn-zhangjiakou.aliyuncs.com/res/Q35O8L7JP4AWO9Vb/img/f722358d-3da0-4dfc-b822-80690a96cb4a.png?Expires=1710387246&OSSAccessKeyId=LTAI1XUz8ModxrPd&Signature=jQkoZwNLO2oe6BmlIWL1IWmaAJ4%3D&x-oss-process=image%2Fresize%2Cw_1280%2Cm_lfit%2Climit_1&
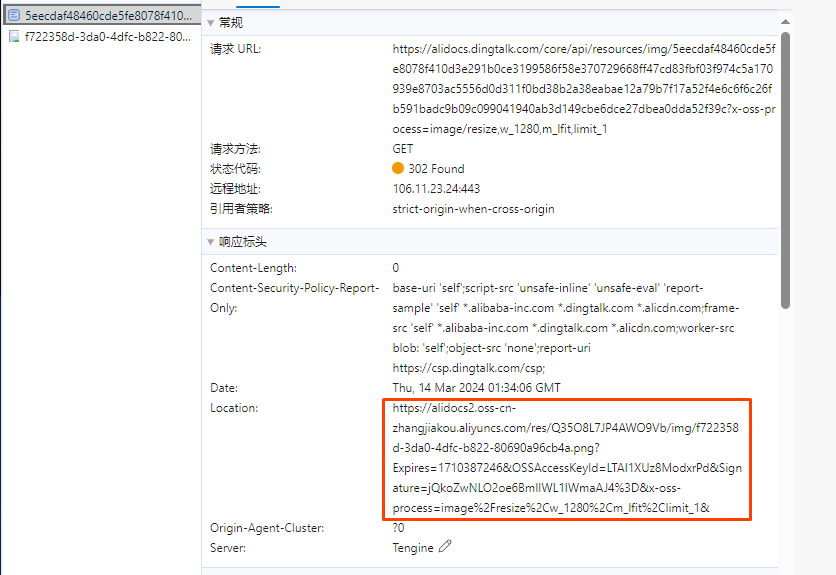
第一个URL需要登陆才能访问,第二个应该可以直接下载。
获取到直链后就可以用下载模块直接下载到指定的位置了,就可以摆脱浏览器默认的下载路径了,但是这不是主要目的,主要还是想弄清楚应该怎么实现。
https://alidocs.dingtalk.com 回头你随便上传一张图片就可以获取到图片的路径了



 京公网安备 11010502053266号
京公网安备 11010502053266号