列表操作,去除不符合正则的内容,去除失败
墨尹琳
创建于 2025-06-09 19:26
步骤:
1. 由OCR或文本选中获取text处理成列表,然后对列表的每一项进行文本处理去掉零宽字符、去除前后空白内容后经由正则替换输出为列表。
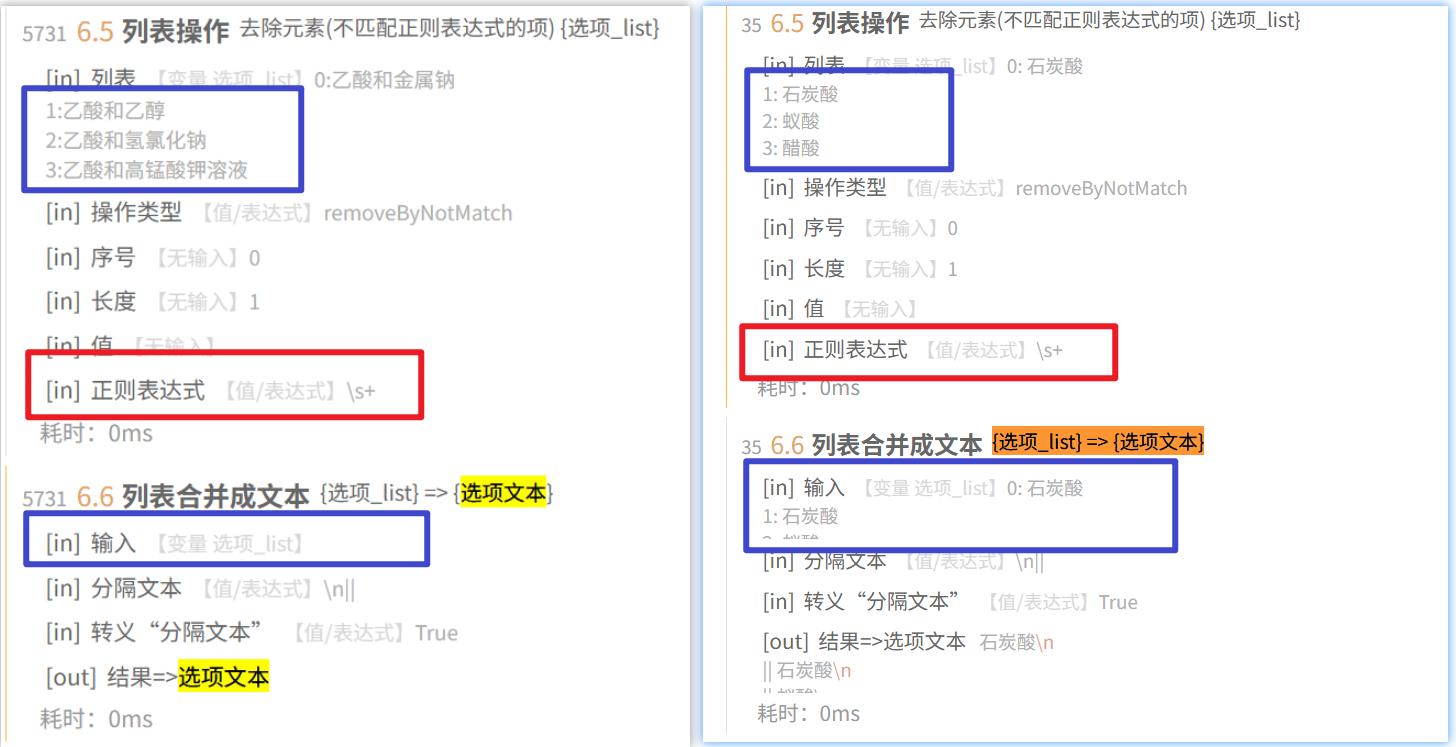
2. 通过列表操作,移除不符合正则的内容,正则为\s+ 理论上每个项都没有空白字符,应该都会被移除吧
3. 结果 由OCR取得的文本,全部被移除,由获取文本取得的文本,没有被移除
我的问题:
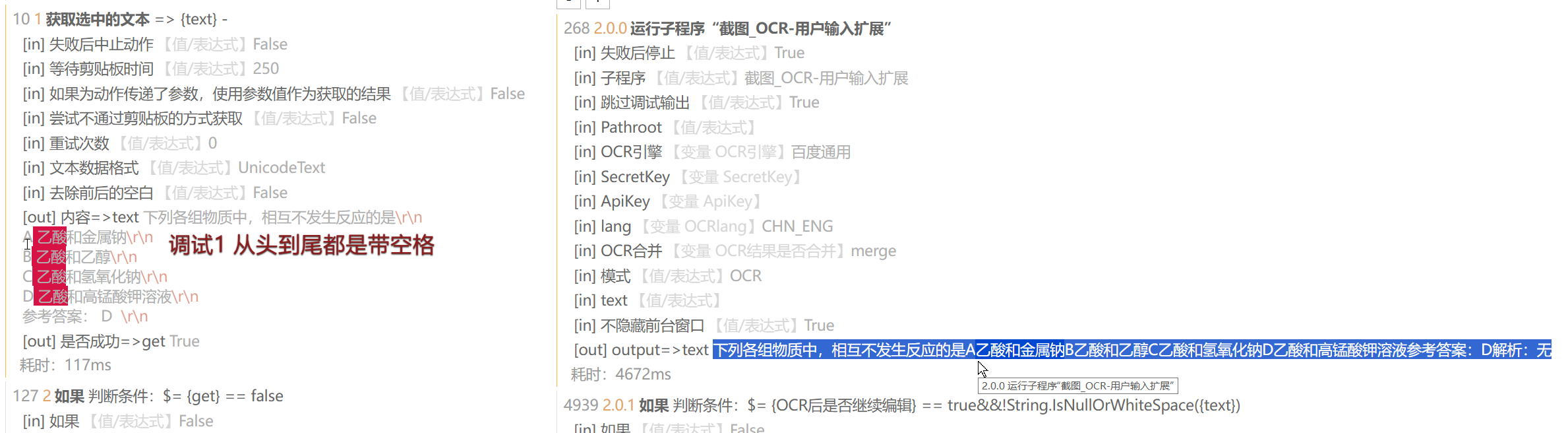
对同一内容一个OCR,一个获取,得到的文本内容只是前者没有换行符,后者有换行符的区别,但是我全部都经过文本处理去除了零宽字符和换行符,理论上两个文本是完全一样的,但结果却是初始文本有换行符,然后经过文本处理去除掉空白字符仍没有被去除掉,而我在调试记录中完全看不出两者有什么区别,说明一下,以下截图是选取的两次不同文本,但实际上对同一文本分别OCR和获取也是一样的结果
其实我是想用\S+去除掉空行的,但是没注意写成了\s+,但是他却没有把不包括空白字符的项目给移除,导致我直到增加了OCR功能输出空白才发现,除了零宽字符它难道还有什么不可见的符号吗
墨尹琳
最后更新于 2025/6/9


 京公网安备 11010502053266号
京公网安备 11010502053266号