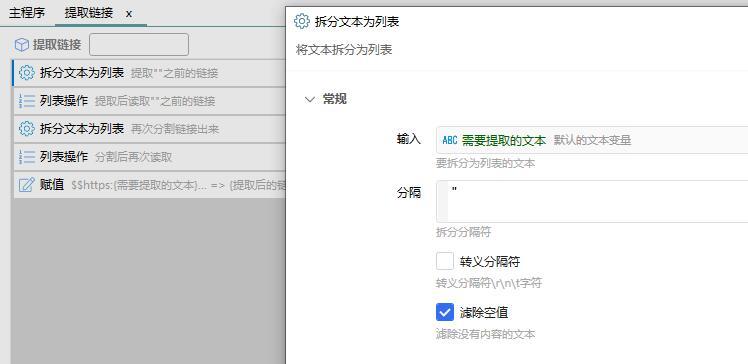
如题,我提取页面的图片地址之后,他的长度是不固定的,所以用长度去截取的话经常出错.
后来我用了...拆分文本为列,里面的按字符拆分,然后在用读取列表...这样写起来代码很长,
希望可以在截取里出一个...
对于正则表达式的话,我看了教程不太理解.毕竟不是这个专业的.希望能跟简单上手一点.谢谢
图片是我自己写的一个子程序,,,就是为了提取""之间的字符串
试试这个子程序:https://getquicker.net/subprogram?id=48c53f5b-d321-4b04-a2a2-08d9548d1780
这个我用了出错了.我按左边取" 在按右边取"
建议把详细的从什么内容里提取什么内容发一下,里面是不是有重复的"之类都会影响解决的办法。
https://getquicker.net/subprogram?id=1ac9d7c7-da55-40e8-ca57-08d8a9658129
开头与结束
这个运行失败呢
建议描述清楚如何失败的,具体的什么现象。这样别人没法判断的。
有的,老哥,我在他原链接下面评论了
内容无固定性只能正则了
谢谢,我用文本_取中间文本 - 已分享的子程序 - Quicker (getquicker.net) 这个子程序后可以提取了

 京公网安备 11010502053266号
京公网安备 11010502053266号