适用于
分类(旧)
文本处理 文件处理 脚本关键词
PecoPeco
等
1 人赞了这个动作
。
更多信息
| 分享时间 | 2026-04-15 15:23 |
| 最后更新 | 2026-04-15 15:23 |
| 修订版本 | 0 |
| 用户许可 | 只读,不可再分享 |
| Quicker版本 | 1.44.31 |
| 动作大小 | 16 KB |
| 最低Quicker版本 | 1.38.15 |
「将文本转换为wps书签代码」
简介
✕ 痛点
01
无书签,阅读困难
获得 PDF 电子版书籍时没有书签,不方便阅读,也无法快速跳转到指定章节。
获得 PDF 电子版书籍时没有书签,不方便阅读,也无法快速跳转到指定章节。
02
WPS 自动生成效果差
使用 WPS 软件自动生成的书签问题多多:层级错误、页码错误、名称错误、漏页等等。
使用 WPS 软件自动生成的书签问题多多:层级错误、页码错误、名称错误、漏页等等。
💡 因此,想要利用 Quicker 动作实现手动可控的书签生成功能,确保每一级书签都准确无误。
视频教程:
✓ 解决方案:四步流程
1
获取目录文本 — 将目录页 OCR 识别得到目录文本
2
文本格式转换 — 对目录文本进行数据清洗,转换为标准格式
3
生成书签代码 — 将标准格式文本转换为书签代码文件 .XML
4
导入书签代码 — 将书签文件导入到 PDF 中
使用方法
📋 流程速览
① OCR 识别目录
→
② 记录起始页码
→
③ 运行动作清洗
→
④ 手动检查修正
→
⑤ 输入页码偏移
→
⑥ 保存 .xml
→
⑦ WPS 导入 ✅
1
📝 获取目录文本(OCR 识别)
将目录页 OCR 识别得到目录文本,然后打开电脑记事本,将识别到的文本粘贴到记事本中。
⚠️ 注意:市面上(包括 Quicker 内)有很多方法可以实现 OCR 识别,此动作不包含此操作,需用户自行处理完成。
最简单的办法:把目录页截图,并把下面第3步中标准格式模板发送给AI,让AI自动生成。
指令:这是一个标准目录格式【复制标准格式替换掉】,请将我提供你的目录页截图转换为这种标准形式文本。
最简单的办法:把目录页截图,并把下面第3步中标准格式模板发送给AI,让AI自动生成。
指令:这是一个标准目录格式【复制标准格式替换掉】,请将我提供你的目录页截图转换为这种标准形式文本。

2
📄 确认目录起始页码
打开 PDF 文档,翻到书籍目录第一页。在 WPS 左下角查看此页对应整个文档第几页。
📌 示例:目录第一页在 WPS 左下角显示为第 11 页,则记录该数字为 11。

3
🧹 运行动作 — 数据清洗
打开电脑记事本,打开第一步中保存的文件。选中待处理的文本,运行该命令。
此时会执行数据清洗,把数据清洗为以下标准格式:
第1章一级标题……………………………………1
1.1二级标题………………………………2
1.1.1 三级标题…………………………3
第2章一级标题……………………5
2.1二级标题………………6
2.1.1 三级标题 ………………………………7
第3章一级标题………………9
3.1 二级标题…………………………………………10
3.1.1 三级标题………11
效果如下图所示 ↓

4
🔍 手动检查 — 修正格式错误
运行后会弹出窗口,显示清洗后的文本。请仔细检查,如有不符合标准格式的内容需手工调整。
⚠️ 格式错误有无数种,无法保证每种都能识别,因此需要手动微调。后续欢迎反馈错误类型,将不断迭代优化。
🐛 示例:上图清洗结果中存在未识别到的小错误——多余字符 "z",删掉即可。
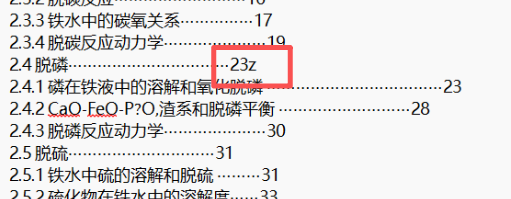
✅ 检查无误后,再次选中所有文本(不全选则修改无效),点击"下一步"。
5
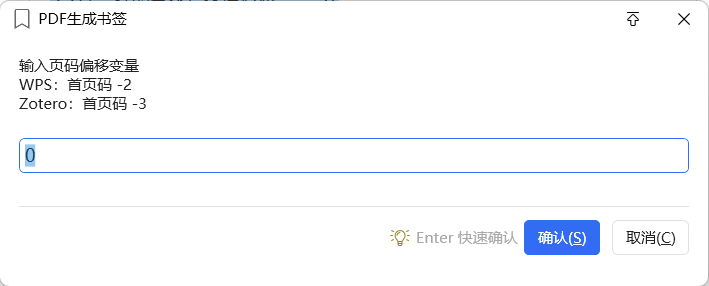
🔢 修改真实页码
点击"下一步"后会出现页码设置界面,需要输入偏移值。
页码计算公式:
WPS 导入:
第2步页码 − 2 = PDF 真实页码
Zotero 导入:
第2步页码 − 3 = PDF 真实页码
6
💾 保存为 .xml 文件
确认页码后,动作会生成书签代码。保存该文件,并将文件后缀从
.txt 修改为 .xml。

7
📥 导入书签到 PDF
在 WPS 中打开 PDF 文档,执行以下操作导入书签:
路径:点击左侧书签按钮 或 快捷键
Alt + Shift + 1 → 选择「导入书签」→ 选择第 6 步生成的 .xml 文件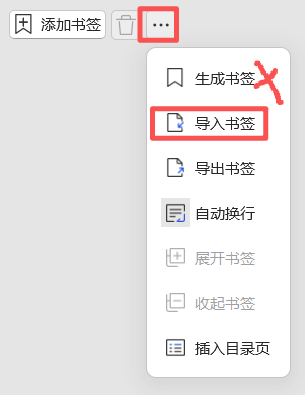
8
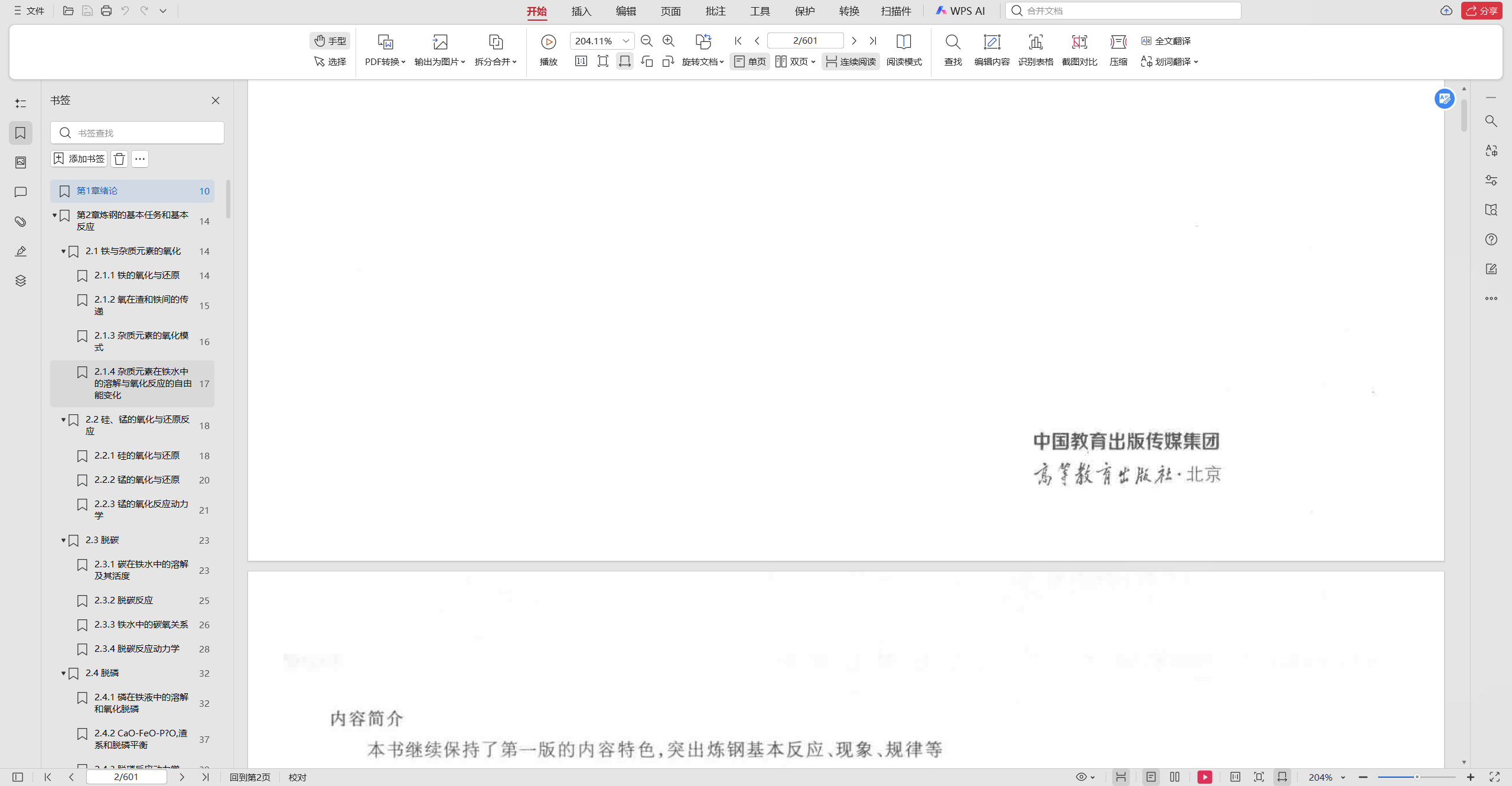
🎉 完成 — 查看效果
书签已成功导入,左侧书签面板中可以看到完整的层级结构,点击即可快速跳转到对应章节。
最近更新
| 修订版本 | 更新时间 | 更新说明 |
|---|---|---|
| 0 | 2026-04-15 15:23 |
最近讨论
暂无讨论

 京公网安备 11010502053266号
京公网安备 11010502053266号