适用于
分类(旧)
示例更多信息
| 分享时间 | 2022-08-09 17:49 |
| 最后更新 | 2022-08-09 17:49 |
| 修订版本 | 0 |
| 用户许可 | -未设置- |
| Quicker版本 | 1.34.15 |
| 动作大小 | 301 B |
简介
为了让正则的编写更加便捷、好记,且更适合中文环境,我尝试自定义了一系列正则语法。
这些自定义的语法,可以在动作 超级文本替换 中使用。本文内容可能有些啰嗦,心急的小伙伴可以直接拉到最后的“速查表”。
注:本文只讨论 Quicker(.NET风格) 的正则。
简写字符类
在中文环境下,一些经常会用到的字符类,正则本身并没有提供像 \s \d 这样的简写形式。比如,匹配汉字 [\u4E00-\u9FF] ,匹配 ASCII 字符 [\x00-\x7F] ,匹配非 ASCII 字符 [^\x00-\x7F] ,等等。这些方括号字符类写起来比较麻烦,而且不好记忆。为此,我给这些字符类提供了简写形式。
\e 匹配英文字母,\h 匹配汉字。两者都有个大写形式,\E 匹配 ASCII 字符,\H 匹配非 ASCII 字符。
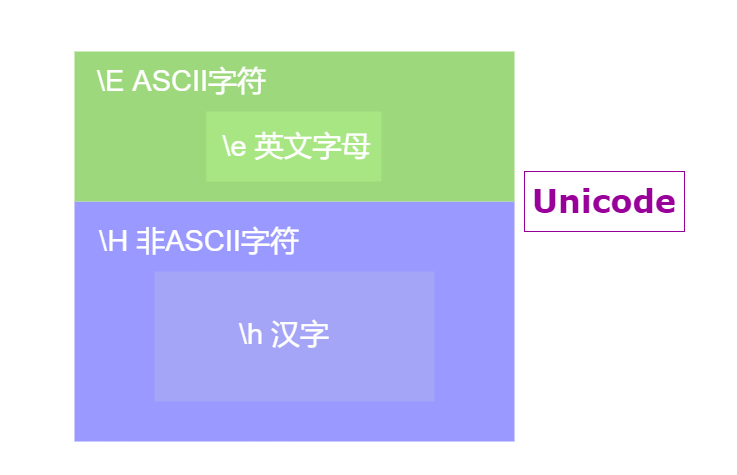
简写形式中的 e 和 h ,就是 en(英) 和 han(汉) 的意思,很好记忆。两个大写形式也不难记,因为它们都是对小写形式的语义扩展。如果是在中英文环境下,可以理解为:
\e 匹配字母,\E 匹配英文字符
\h 匹配汉字,\H 匹配中文字符
这几个简写字符类在处理中英文混合文本时,非常好用。说到这里,就不得不提到一个很常见的简写字符类 \w 。
\w 其实是有两套标准的,ASCII 标准和 Unicode 标准。前者匹配字母、数字以及下划线,等价于 [a-zA-Z0-9_] ;后者除了匹配 [a-zA-Z0-9_] ,还会匹配到非英语的“单词字符”。比如在 C# 和 Python 中,\w 默认是 Unicode 标准的,也就是说它匹配的是所有文字系统中的“单词字符”,其中就包括汉字、日文假名、希腊字母等等,而不仅仅是匹配 [a-zA-Z0-9_] 。
如果你只是在英文小说中使用 \w ,它是哪一种标准其实无关紧要。但在处理中英混合文本时,Unicode 标准的 \w 就比较尴尬了。宽泛而笼统的字符范围,显得有些不伦不类。相比之下,使用 \e ,\h ,\E ,\H 明显要精准而优雅的多 。
此外还定义了两个中国特色的简写字符类:\c 匹配中文小写数字,\C 匹配中文大写数字。
这些简写字符类的使用示例,请查看文末的速查表。
边界断言
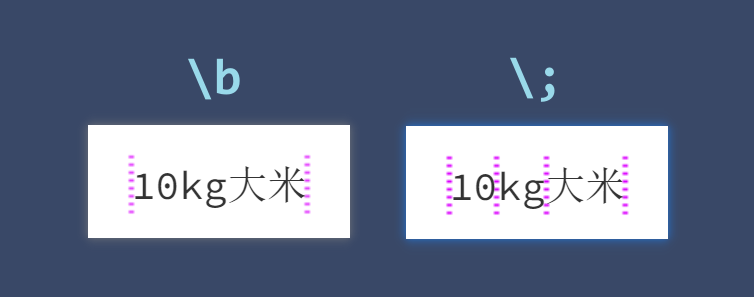
\b 与 \w 是对应的,所谓“词边界”就是 \w+ 的两侧。

既然 \w 步子迈大了,\b 自然也蛋疼。比如字符串 “10kg大米” 中,你可能会下意识的认为 "kg" 与 "大米" 两者之间的间隙属于“词边界”,其实不然。这个例子中,\w+ 可以匹配到所有字符,字母、数字、汉字之间根本不存在“词边界”,\b 只能匹配到字符串的开头和结尾。这样的边界断言是反直觉的。
作为 \b 的替代,我定义了一个更直观的类型边界 \; ,反斜杠+分号,匹配字母串、数字串、汉字串的开头或结尾。在上面这个例子中,“10” 、”kg"、"大米" 两侧的位置都是类型边界。
行锚点以及换行符问题
锚点 ^ 和 $ 有两种行为模式:① 匹配字符串的开头/结尾,② 匹配每行的开头/结尾。采用哪一种行为取决于是否开启“多行模式”。.NET 正则还支持锚点 \A 和 \Z ,仅匹配字符串的开头/结尾,不受“多行模式”影响。
与之对应,我添加了一对锚点 \< 和 \> ,仅匹配每行的开头/结尾,不受“多行模式”影响。这种锚点的含义是固定不变的,好处是可以避免由于正则选项设置而造成的混淆或错误。此外, \< 和 \> 还有个重要功能:解决换行符问题。
先做个术语说明。在中文语境下,换行符一般是指 \n (new line) ,但有时候又会用来指代行终止符,例如这样的说法:Windows 的换行符是 \r\n ,Linux 的换行符是 \n 。为了避免歧义,下文会把后者称为“行分隔符”。
当我们用正则处理多行文本时,很多人都会想当然的认为多行文本的行分隔符是 \n ,像这样的,"第一行\n第二行\n第三行"。但实际上我们用 Quicker 获取的文本,往往是这样的, "第一行\r\n第二行\r\n第三行" ,行分隔符是 \r\n ,而不是 \n 。这时候问题就来了,使用 $ 的正则有可能匹配不到预期的内容。
举个例子,用正则 \d$ 去匹配字符串 "123\r\n456\r\n789" ,想要提取每行最末尾的数字,却发现匹配不到 3 和 6 ——确认开启了“多行模式”。
为什么会这样呢?这是因为正则引擎不会把整对的 \r\n 视为行分隔符,它只认 \n ,\r 不过是一个普通字符。所以在正则引擎眼中,第一行和第二行的最后一个字符是 \r ,而不是数字,所以该正则只能匹配到第三行的 9 。

该问题有两个解决办法,一是预先把文本中的 \r\n 统一替换为 \n ,二是把正则改为 \d(?=\r?$) 。(动作 超级文本替换 就提供了一个选项:自动把输入文本的行分隔符统一为 \n ,完成文本处理后,会自动转换回 \r\n 输出)
相比之下,用 \> 就没有这个烦恼,你不用关心行分隔符是什么,也不用担心是否忘记开启了”多行模式“。 无论是"123\n456\n789" 、"123\r456\r789" 还是 "123\r\n456\r\n789" ,\d\> 都能匹配到每行末尾的数字。
任何字符
点号 . 可以说是最简单的字符类了。它同样有有两种行为模式:① 匹配除了 \n 之外的任何字符,② 匹配包括 \n 在内的任何字符。采用哪一种行为取决于是否开启“单行模式”。类似地,我分别为两种匹配行为定义了单独的字符类:\o 和 \O ,反斜杠 + 字母 o 。
小写 \o 匹配除了 \r , \n 之外的任何字符,大写 \O 匹配包括 \r, \n 在内的任何字符。这两个字符类相比于 . ,除了不受“单行模式”影响之外,还考虑了字符 \r 。在以 \r\n 为行分隔符的文本中,要比 . 好用。
举个例子,给定字符串 "123\r\n456" ,如果用 .+ (点号不匹配 \n) 来匹配,会匹配 ”123\r" 和 "456" ,结果文本中夹杂了一个多余的字符 \r 。而使用 \o+ 则会匹配 ”123" 和 "456" 。
更具体一点的例子,假设你想给每行文本添加前后缀,可以这样写:正则 \o+ ,替换为 前缀$&后缀 。如果使用 .+ ,你会得到一个乱七八糟的结果。当然,你也可以写成 [^\r\n]+ ,因为 \o 与 [^\r\n] 是等价的,只不过写起来不如 \o+ 方便。
其实一开始是打算采用字符 a 的,取 all 之意,可惜原生语法存在
\A了。不过字母 o 也还行,毕竟这个语法就是点号.的变体,大家都是圆形的,强行记忆一波。
其他
\Q 放在正则最开头,取消所有元字符的特殊含义,按照字面意思匹配字符本身。例如,\Q1+2*3 等同于 1\+2\*3 。这是从 Perl 借过来的语法。
在 .NET 正则的原生语法中,\e 匹配转意符(escape)。我定义的语法直接将其覆盖掉了,这样会有什么影响吗?没影响。因为对大多数正则使用者而言,基本没有匹配这个控制字符的需求。再者,这类控制字符还可以用 \x1B 或 \u001B 这样的语法来匹配。
速查表
| 语法 | 匹配 | 说明及示例 |
|---|---|---|
| \o | 几乎任何字符 | 匹配除了 \r , \n 以外的任何字符。示例,每行插入前后缀: 【源文本】“123\r\n456" 【正 则】\o+ 【替换为】前$&后 【结果文本】“前123后\r\n前456后” |
| \O | 任何字符 | 匹配包括 \r, \n 在内的任何字符,等同于“单行模式”下的点号 . |
| \e | 英文字母 | 匹配任意英文字母,等价于 [a-zA-Z] |
| \E | ASCII字符 | 匹配任意ASCII字符。示例,提取英文句子: 【源文本】hello, world! 你好,世界! 【正 则】\E+ 【匹配结果】hello, world! |
| \h | 汉字 | 匹配任意汉字(Unicode基本平面) |
| \H | 非ASCII字符 | 匹配任意非ASCII字符。示例,提取中文句子: 【源文本】hello, world! 你好,世界! 【正 则】\H+ 【匹配结果】你好,世界! |
| \c | 中文小写数字 | 等价于 [〇一二三四五六七八九十百千万亿兆] ,示例: 【源文本】第五十八回 潘金莲打狗伤人 孟玉楼周贫磨镜 【正 则】第\c+回 【匹配结果】第五十八回 |
| \C | 中文大写数字 | 等价于 [零壹贰叁肆伍陆柒捌玖拾佰仟亿兆] ,示例: 【源文本】人民币壹仟陆佰捌拾元整 【正 则】\C+ 【匹配结果】壹仟陆佰捌拾 |
| \; | 类型边界 | 匹配字母串、数字串、汉字串的开头或结尾。示例,匹配没有包含在数字串里面的数字: 【源文本】20220122 第22天共220小时 【正 则】\;22 【匹配结果】匹配到第三个和第四个22 【正 则】\;22\; 【匹配结果】只能匹配到第三个22 |
| \< | 行首 | 匹配每行的开始处,即字符串的开头或 \r\n , \r , \n 之后的位置 |
| \> | 行尾 | 匹配每行的结尾处,即字符串的末尾或 \r\n , \r , \n 之前的位置 |
| \Q | 普通匹配 | 放在正则表达式的最开头,消除所有元字符的特殊含义 \Q1+2*3 等同于 1\+2\*3 |
最近更新
| 修订版本 | 更新时间 | 更新说明 |
|---|---|---|
| 0 | 2022-08-09 17:49 |

 京公网安备 11010502053266号
京公网安备 11010502053266号