适用于
分类(旧)
脚本 网络服务 功能更多信息
| 分享时间 | 2020-09-04 16:48 |
| 最后更新 | 2020-09-14 18:36 |
| 修订版本 | 6 |
| 用户许可 | -未设置- |
| Quicker版本 | 1.10.10 |
| 动作大小 | 62.4 KB |
简介
新版https://getquicker.net/Sharedaction?code=5672a523-1889-4dc3-e1ba-08d974e692d3&fromMyShare=True
默认记录上一次的xpath 方便多次提取 自动模式下 进入手动提取也会显示上次的xpath
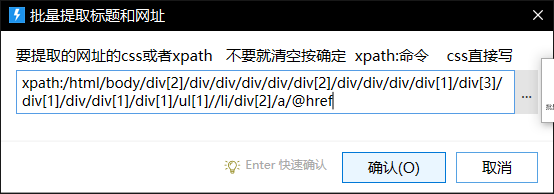
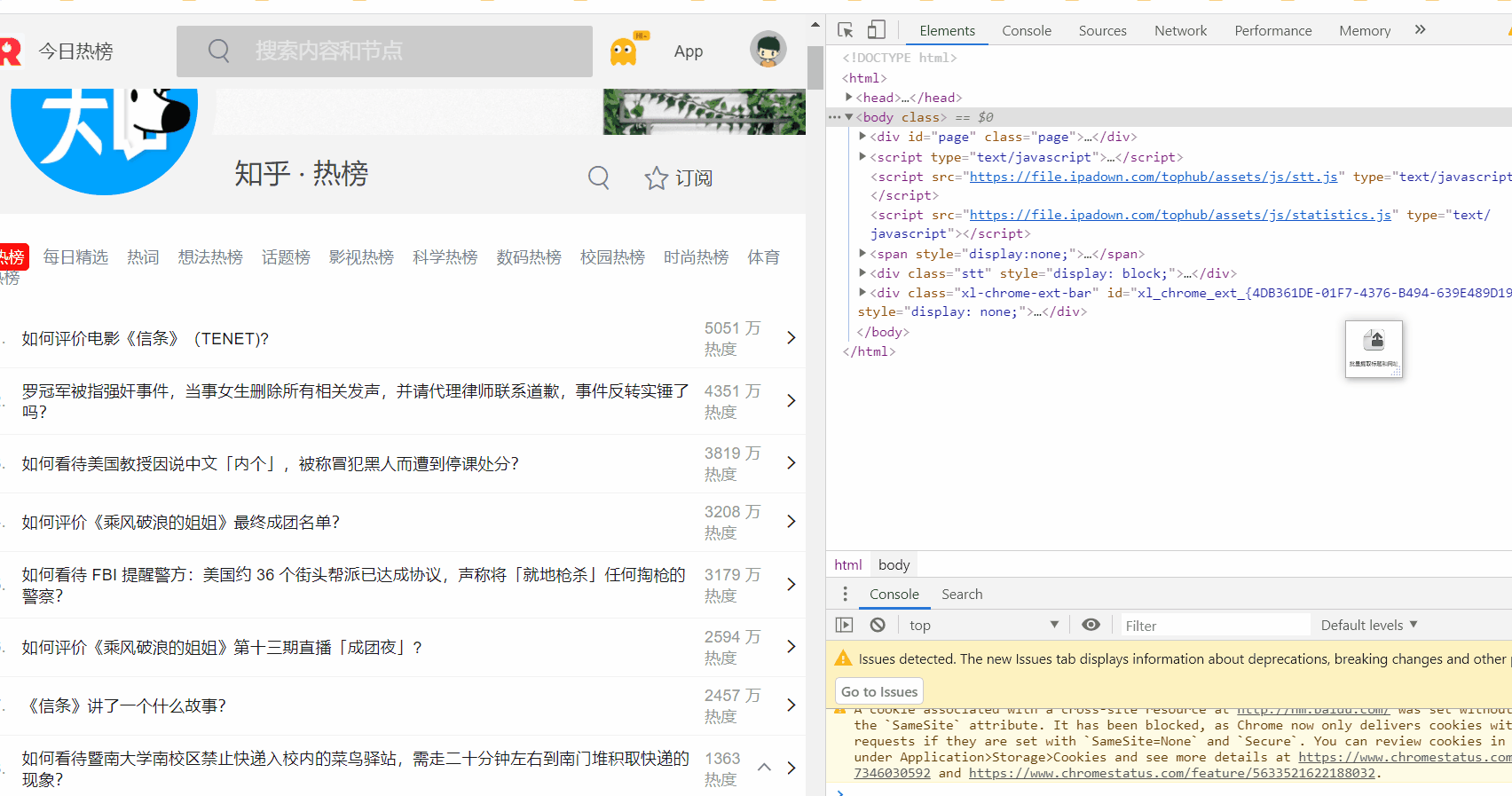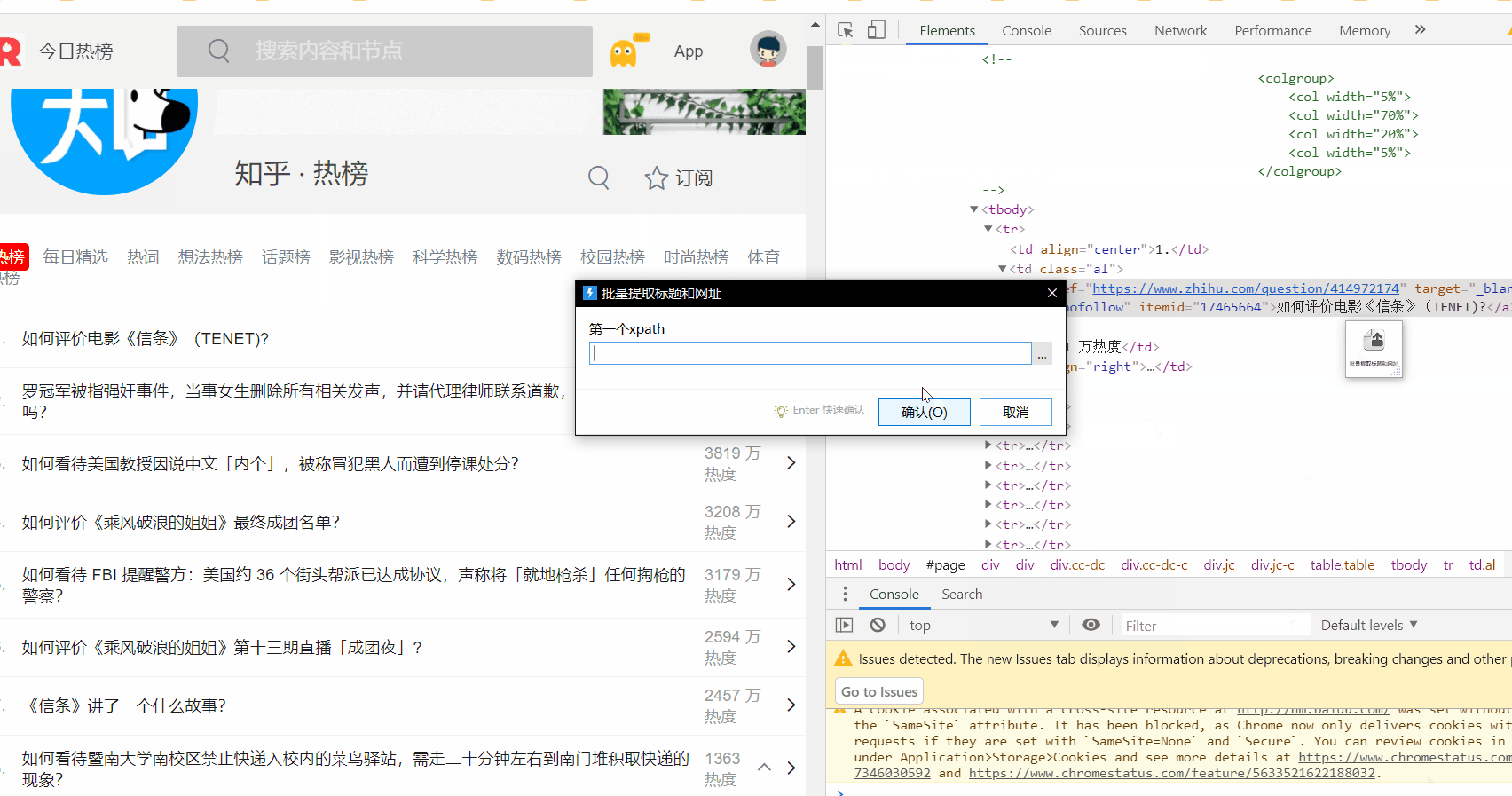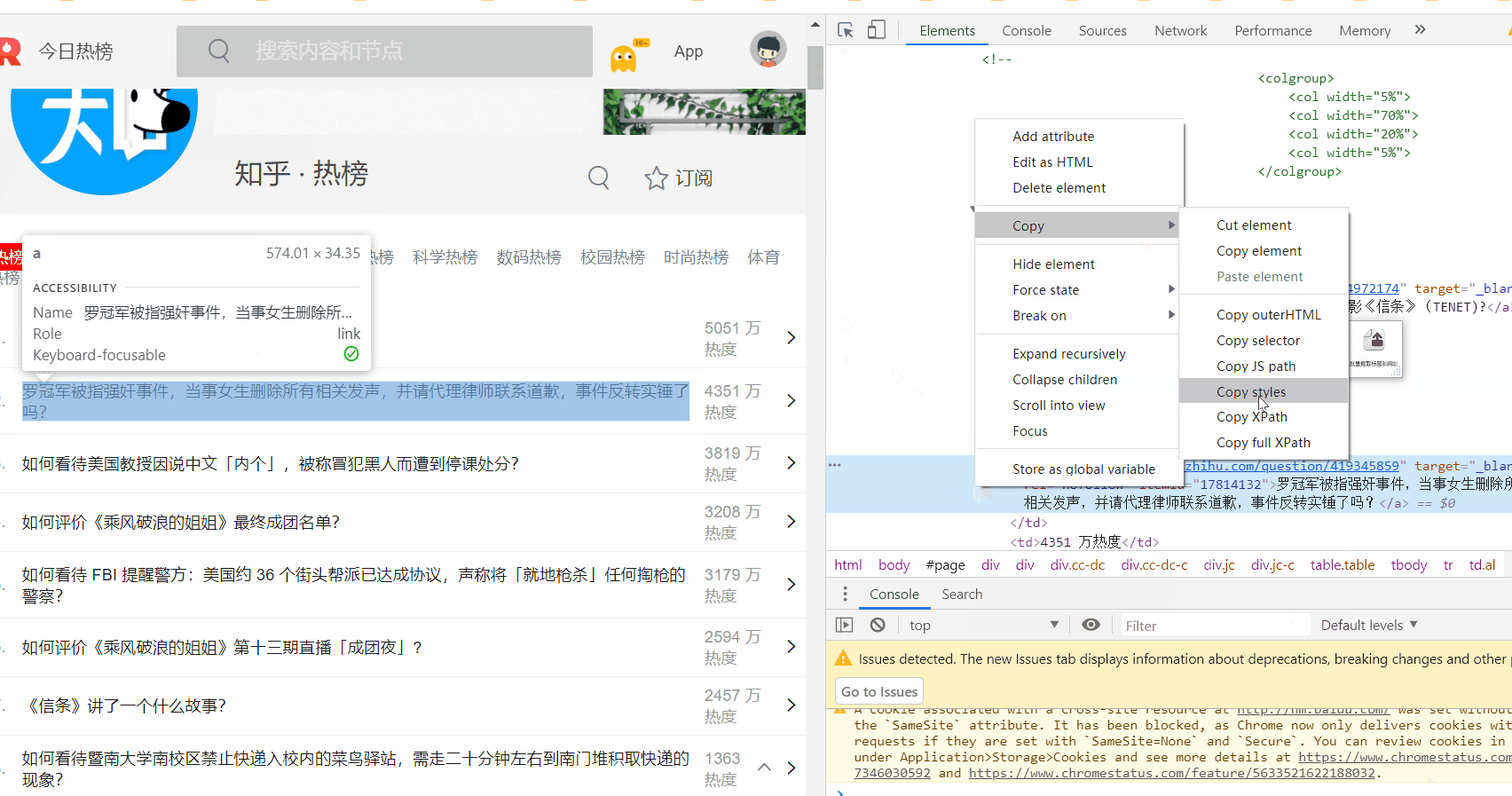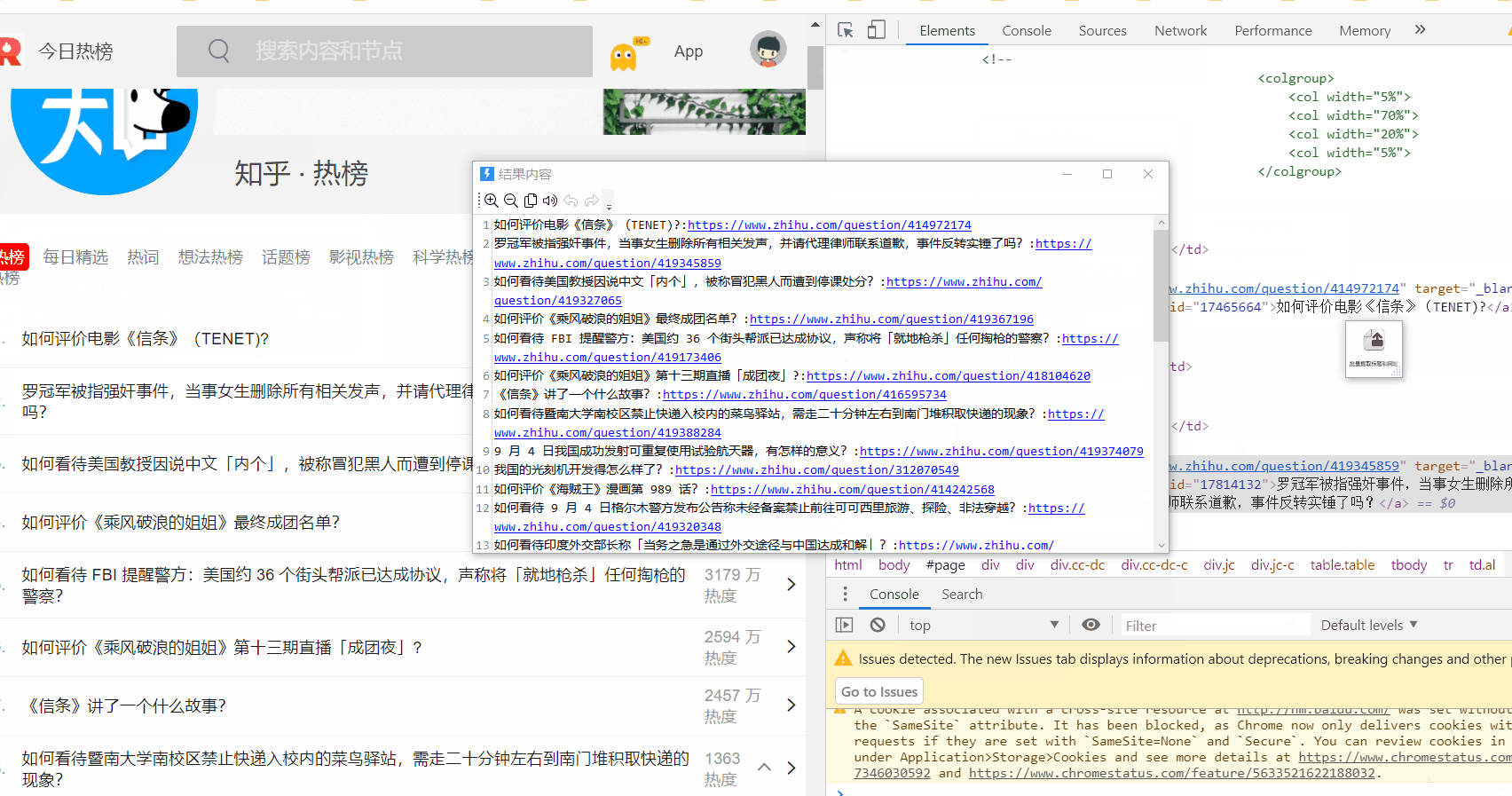
标题就是要提取的纯文本 网址就是要提取的属性(自己看源码 要提取东西为等号后面的 直接就在xpath后面加@等号前面的单词 例如href=“网址” 就写成@href >< 里面的内容直接就用标题提取 看下面的例子)
简单的xpath提取教程: 发现问题的请反馈一下
网址:http://tv.cctv.com/lm/qpl/videoset/index.shtml
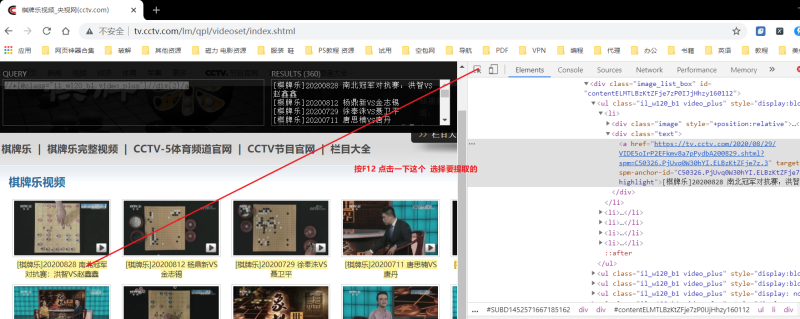
右键复制 复制第一个标题的xpath 再复制第二个标题的xpath
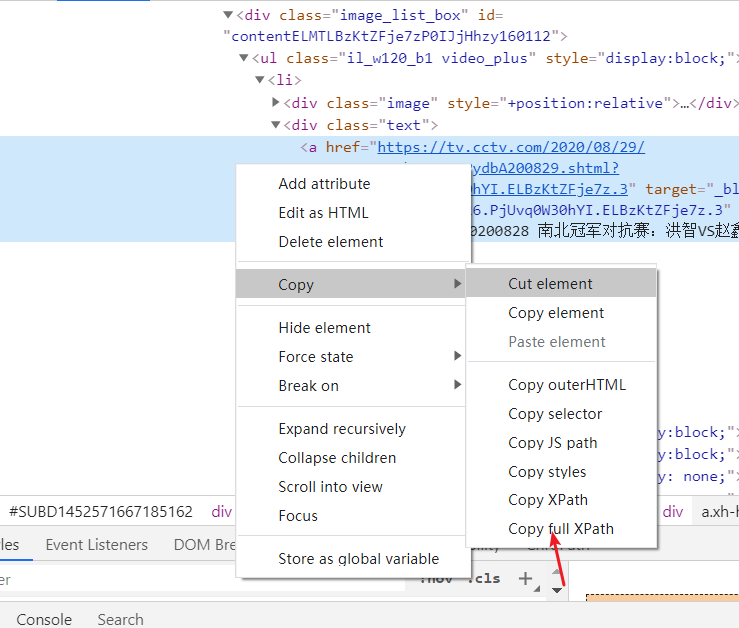
第一个标题:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]/li[1]/div[2]/a
第二个标题:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]/li[2]/div[2]/a
找前面相同的部分
相同的:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]
删除不同部分 /li[1]/div[2]/a-->/li/div[2]/a
结果:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]//li/div[2]/a
按住ctrl点击动作
提取标题就写:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]//li/div[2]/a
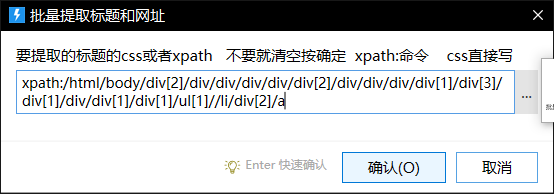
要提取东西为等号后面的 直接就在xpath后面加@等号前面的单词 例如href=“网址” 就写成@href >< 里面的内容直接就用标题提取
提取网址就写:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]//li/div[2]/a/@href
上面的方法一般都用在列表那种,分行(或者分块、列表)的话用下面这种方法
第二个标题-->选择第二行的第二个标题
第一个标题:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[1]/li[1]/div[2]/a
第二个标题:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul[2]/li[2]/div[2]/a (第二行的)
相同部分:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]
删除不同的部分 /ul[2]/li[2]/div[2]/a -->ul/li/div[2]/a
结果:/html/body/div[2]/div/div/div/div/div[2]/div/div/div/div[1]/div[3]/div[1]/div/div[1]/div[1]/ul/li/div[2]/a
(提取的结果有300多 那是因为其他页面的结果也在里面)
这种标题和链接分离的只能手动写 https://tophub.today/
标题和链接分别写一个xpath

标题:
/html/body/div[1]/div[4]/div[4]/div[2]/div[1]/div/div[2]/div[1]/a[1]/div/span[2]
/html/body/div[1]/div[4]/div[4]/div[2]/div[1]/div/div[2]/div[1]/a[2]/div/span[2]
结果:/html/body/div[1]/div[4]/div[4]/div[2]/div[1]/div/div[2]/div[1]/a/div/span[2]
网址:
/html/body/div[1]/div[4]/div[4]/div[2]/div[1]/div/div[2]/div[1]/a[1]
/html/body/div[1]/div[4]/div[4]/div[2]/div[1]/div/div[2]/div[1]/a[2]
/html/body/div[1]/div[4]/div[4]/div[2]/div[1]/div/div[2]/div[1]/a/@href (提取等号后面的东西都写 @等号前面的东西)
自动处理 (自动去重复)
多行的排列的话第一个标题xpath要复制第一行的第一个 第二个标题xpath要复制第二行的第二个
软件会自动根据这2个xpath合成用来提取的xpath
网址:https://tophub.today/n/mproPpoq6O
吾爱
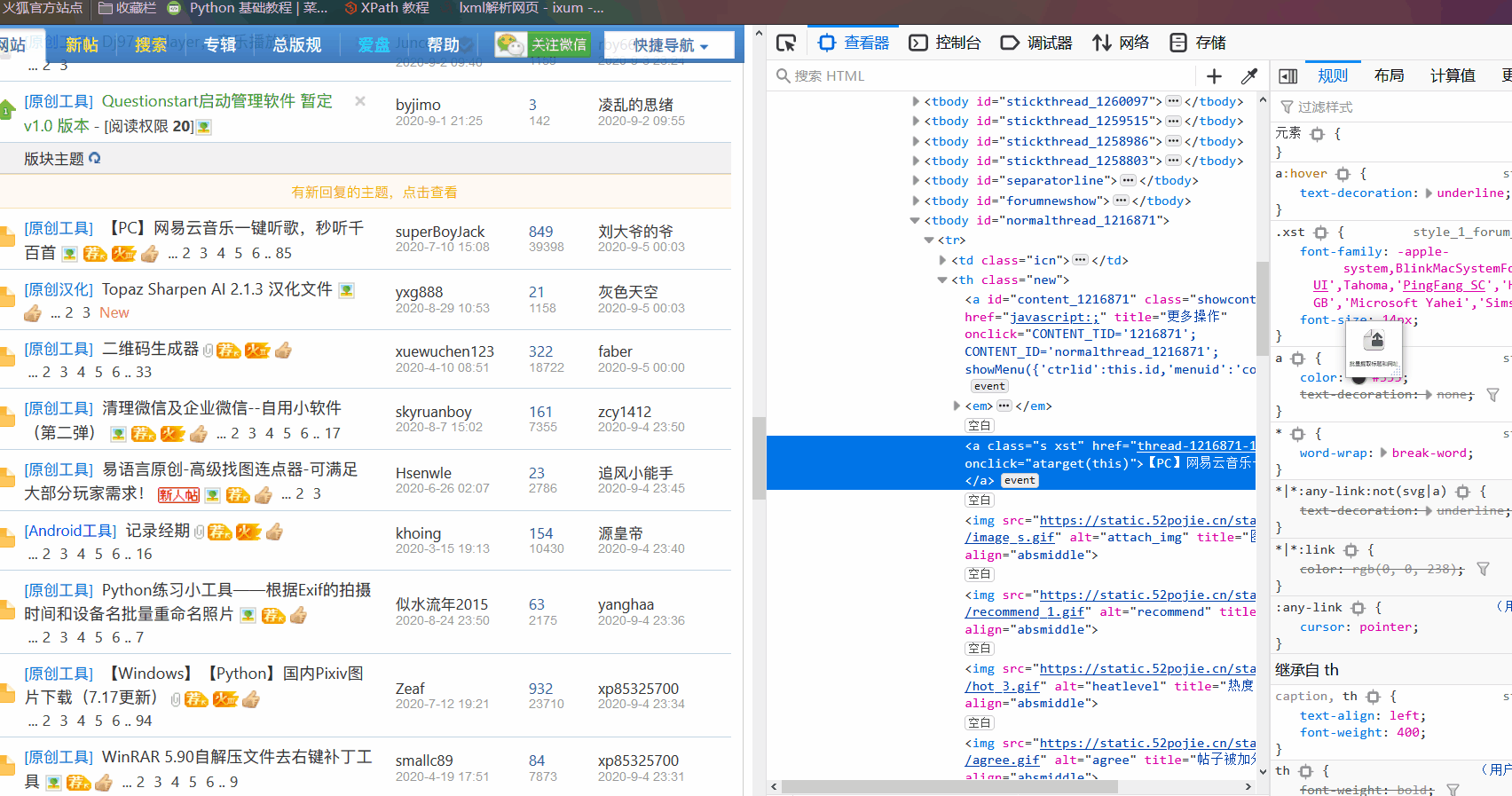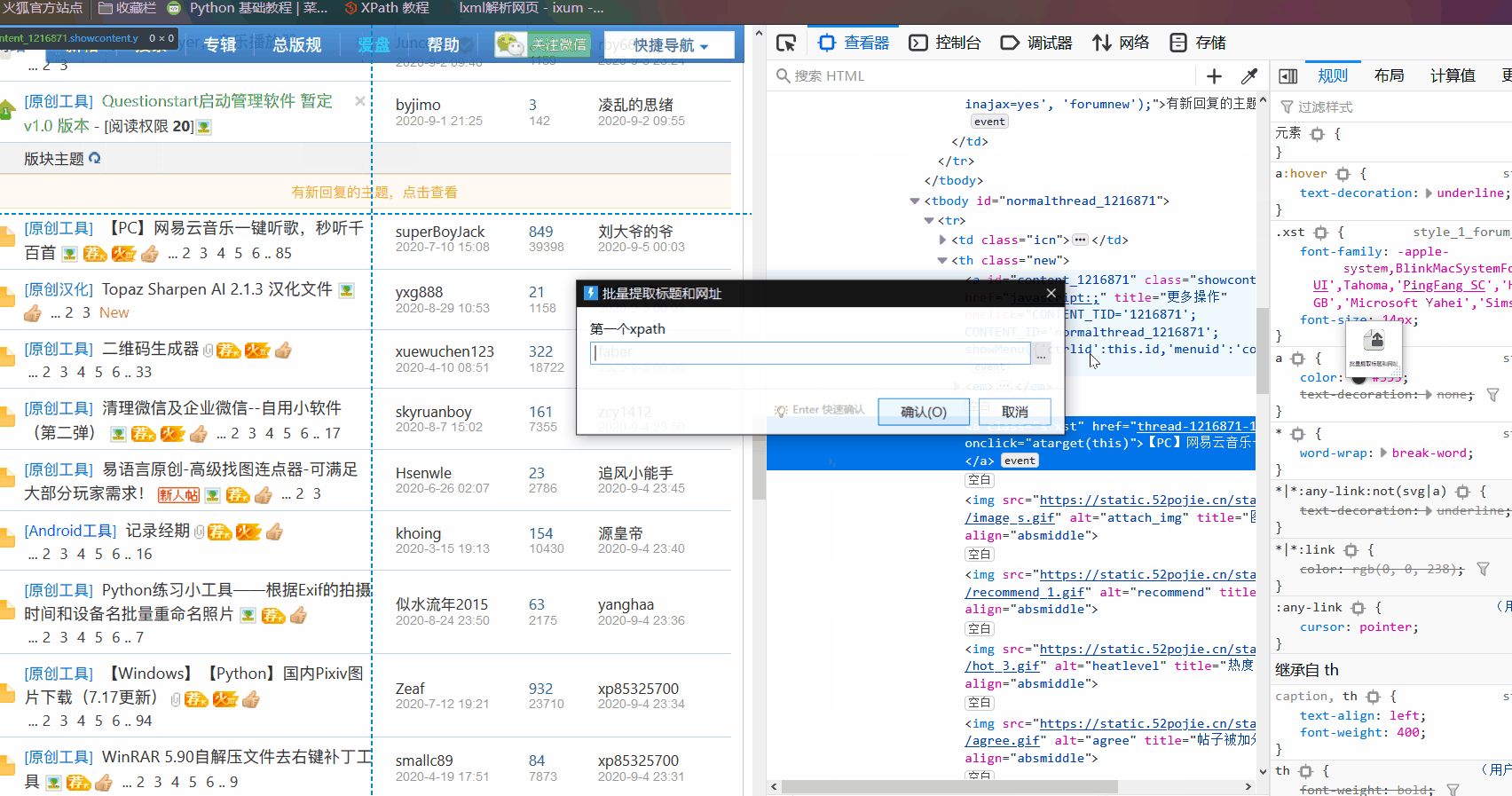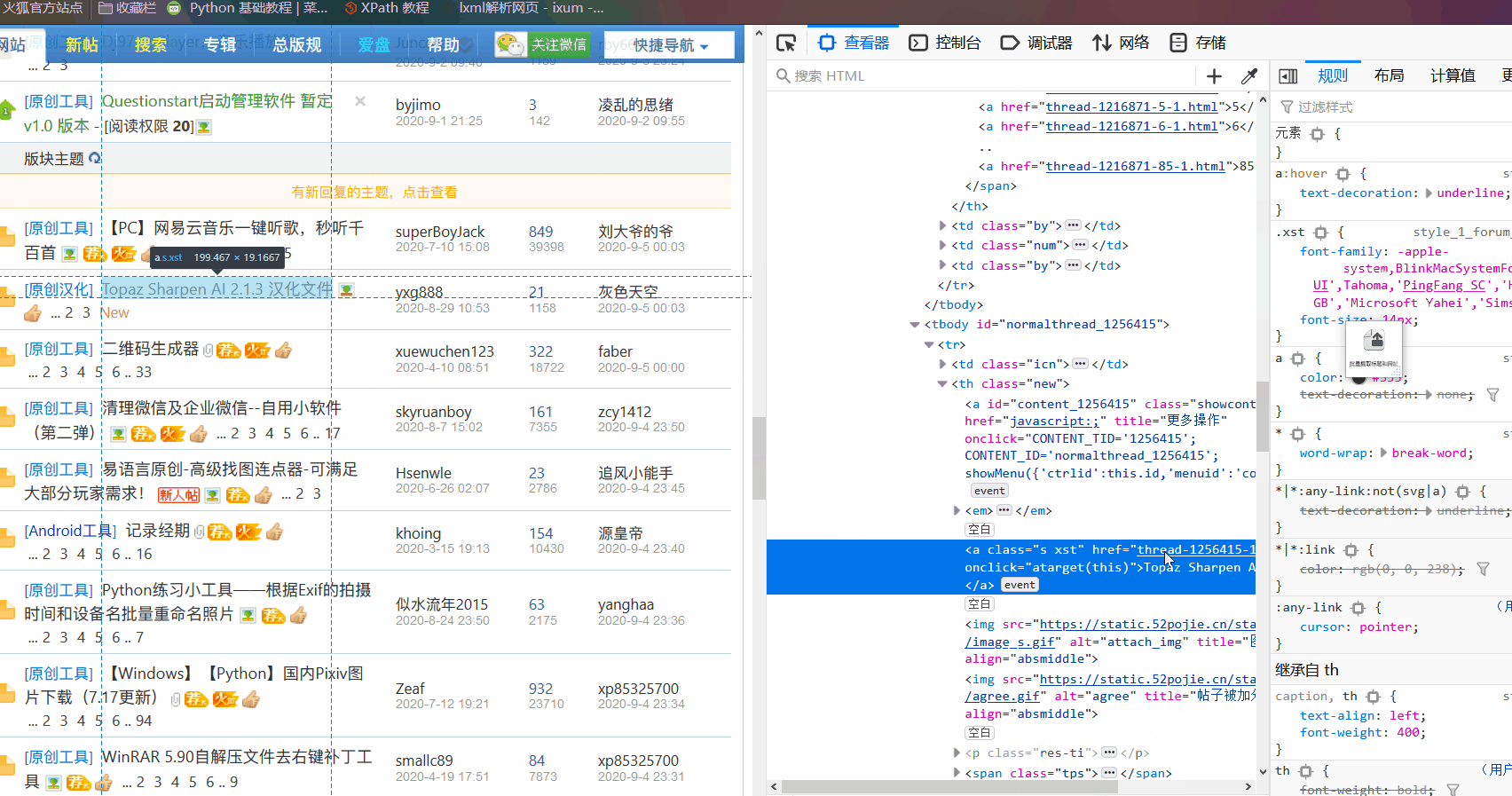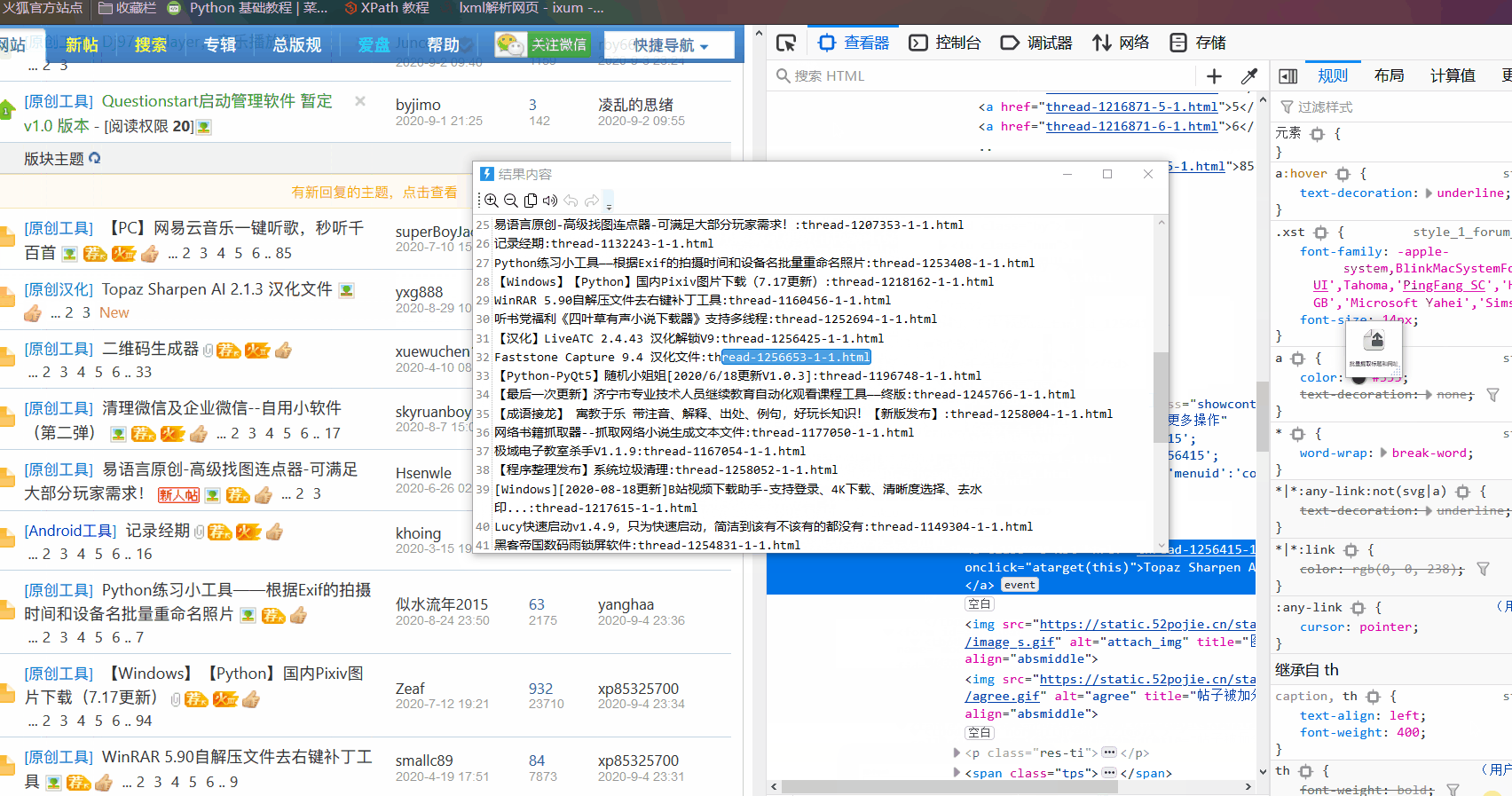
多列表的看自己 要一个列表的 就复制同一个列表的标题
要全部列表的就复制 第一个列表的第一个标题 第二个列表的第二个标题
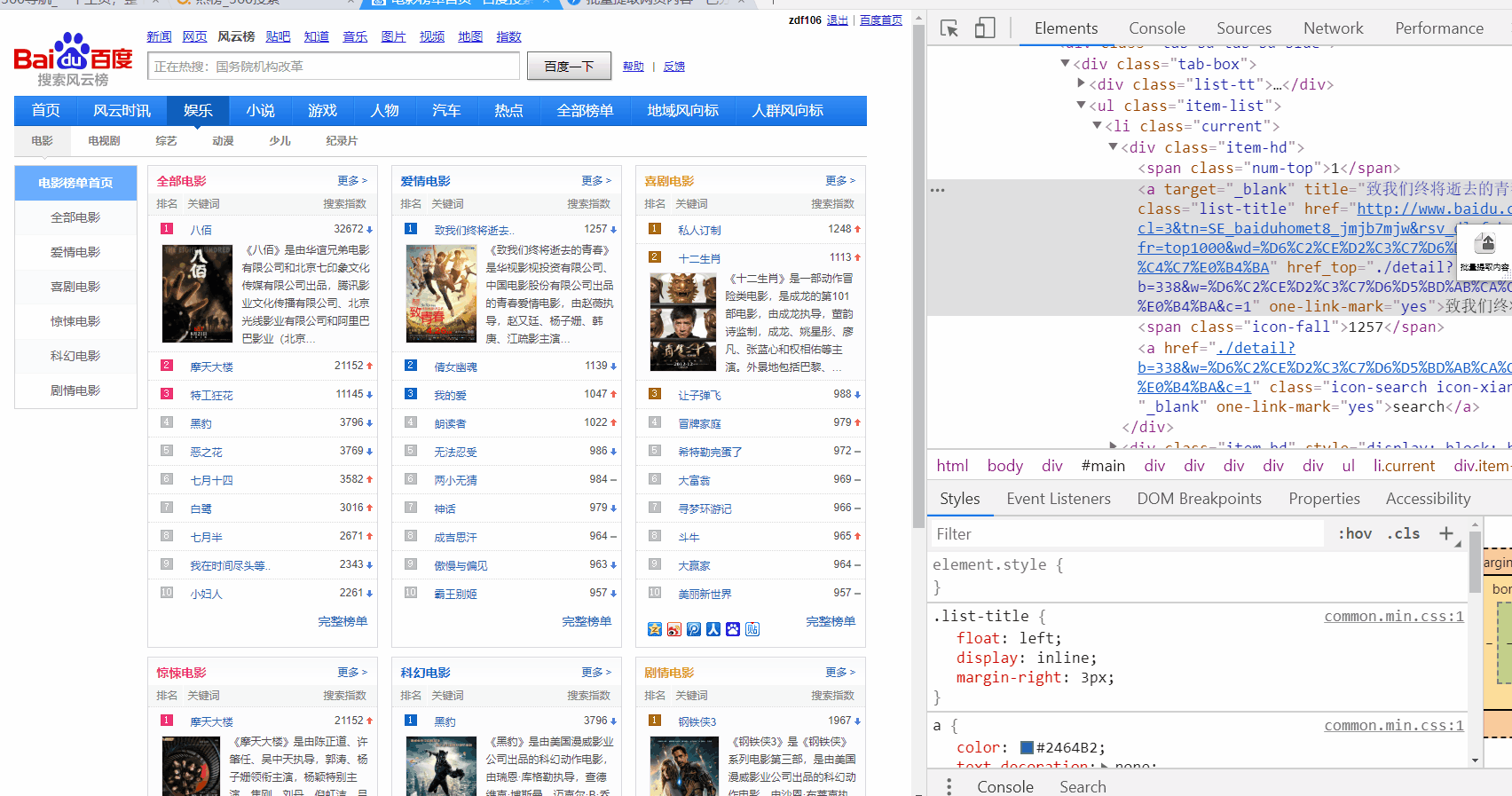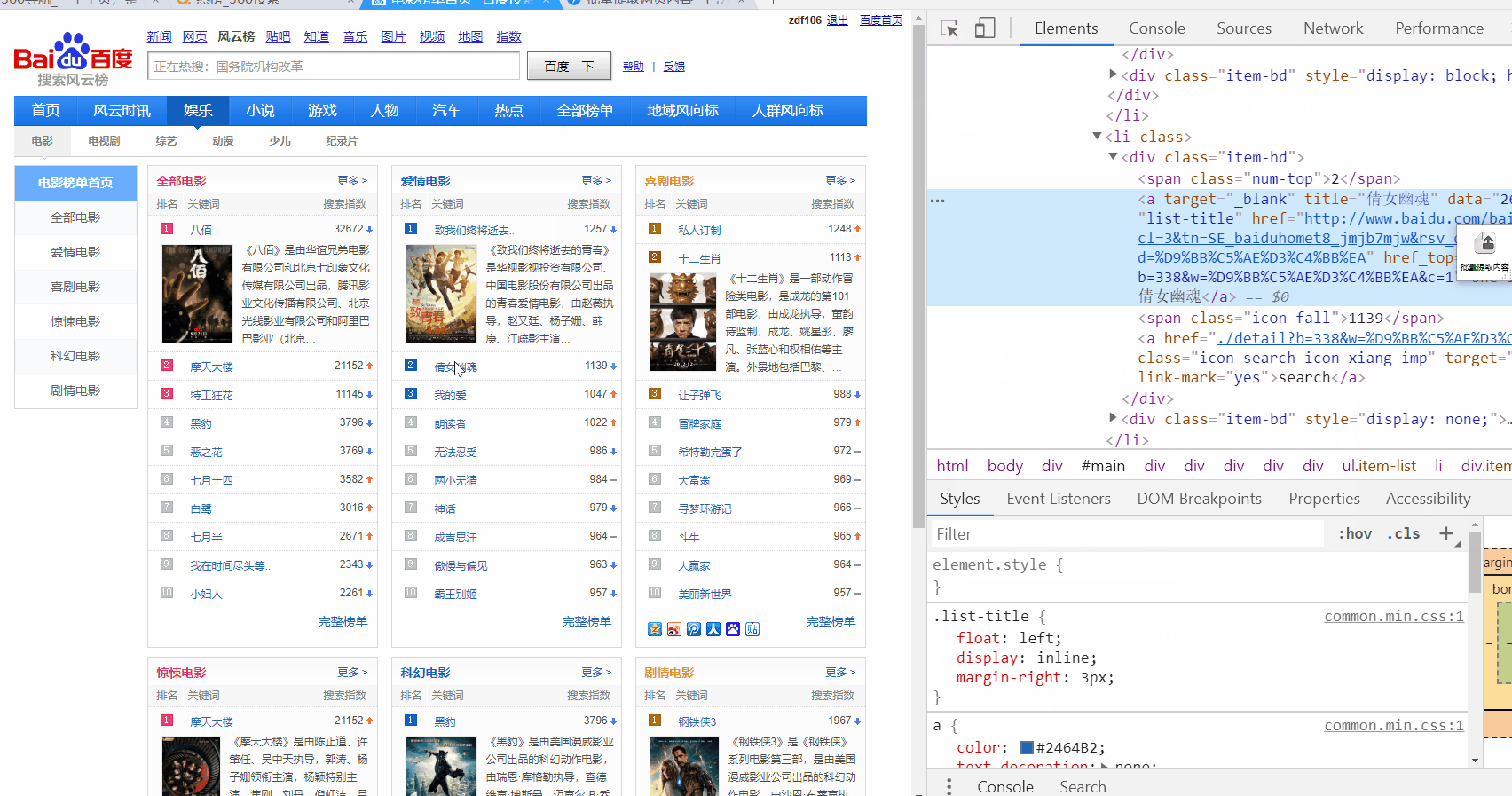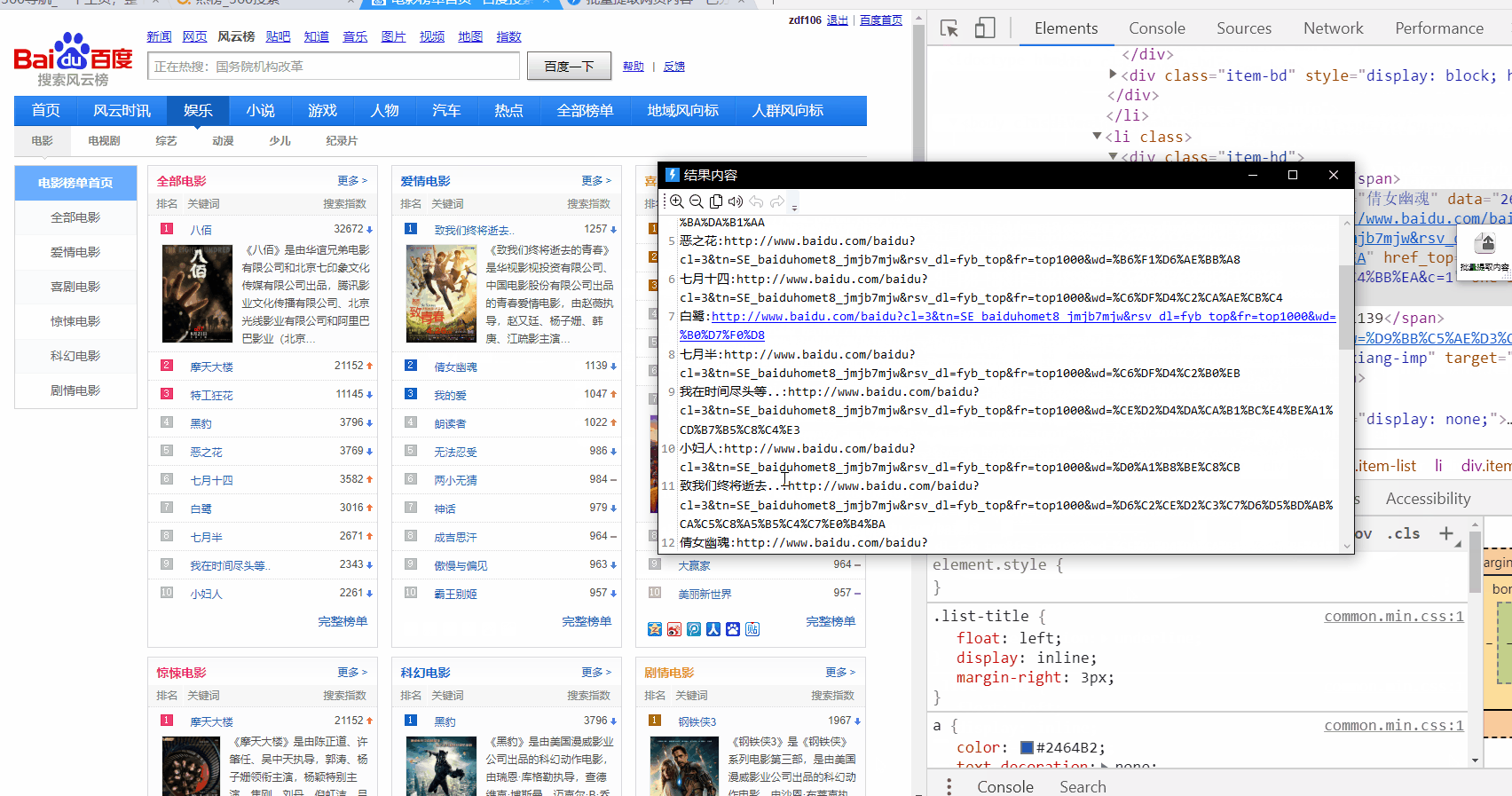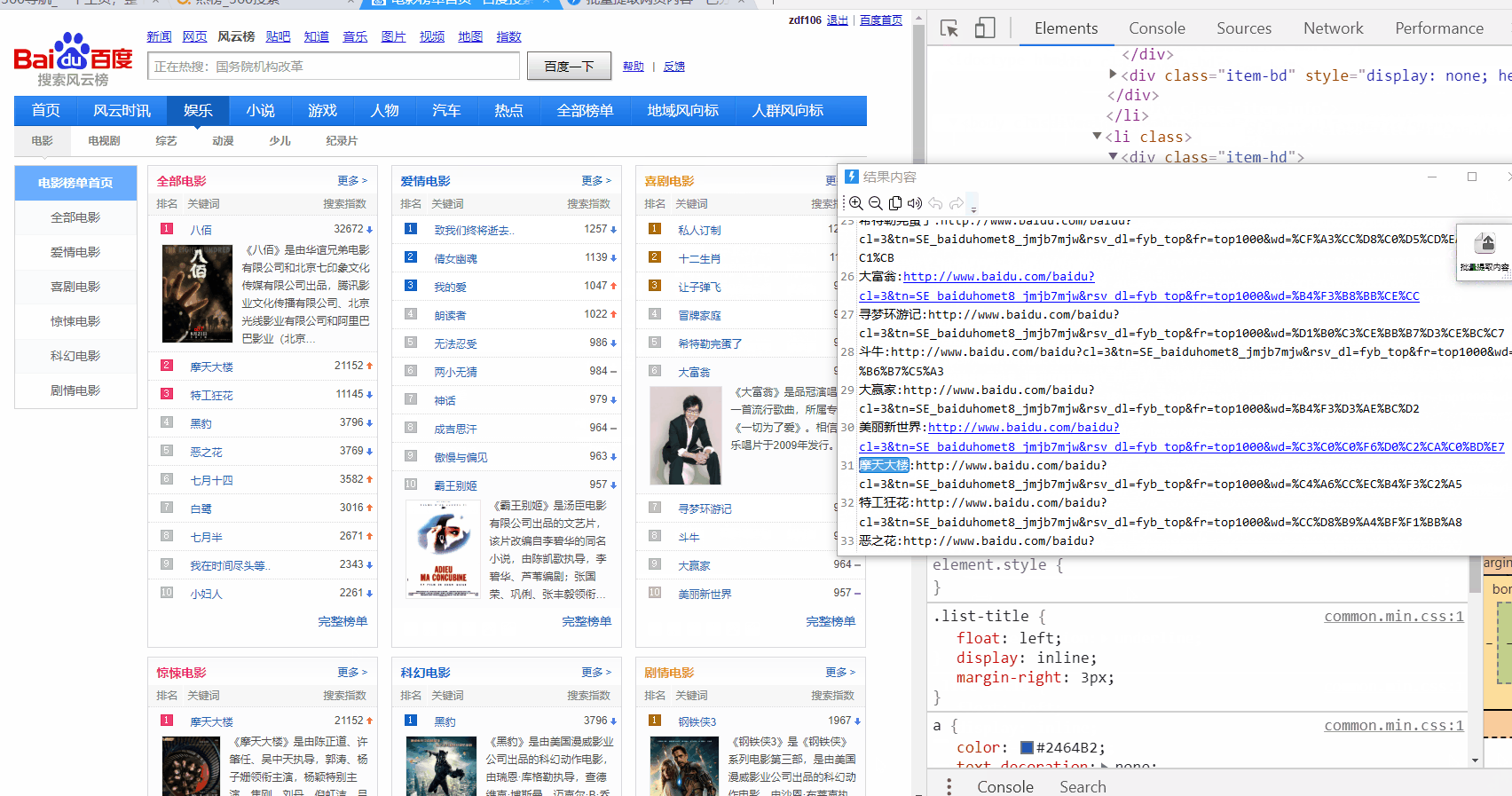
http://top.baidu.com/category?c=1&fr=topindex
只提取一列: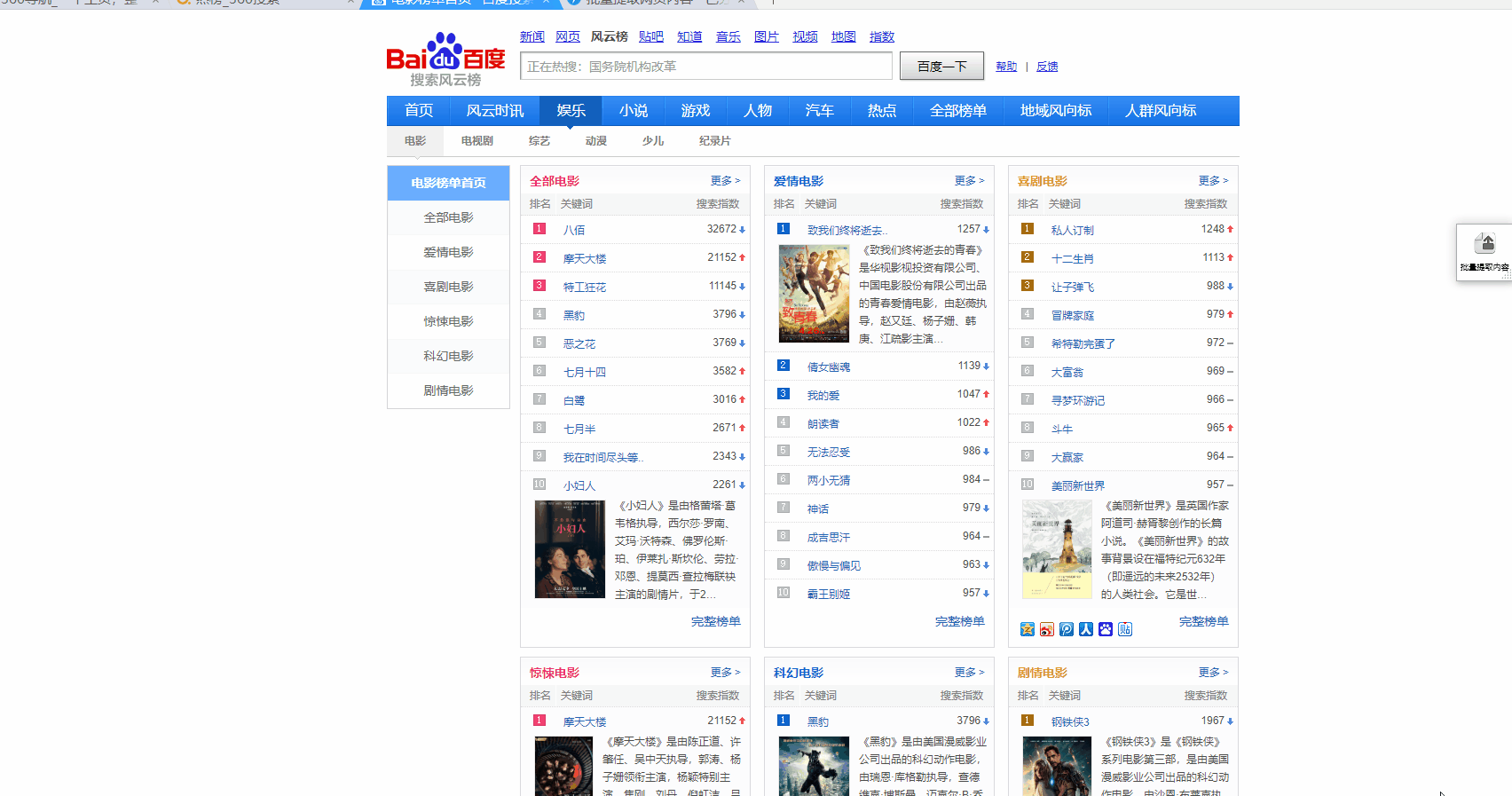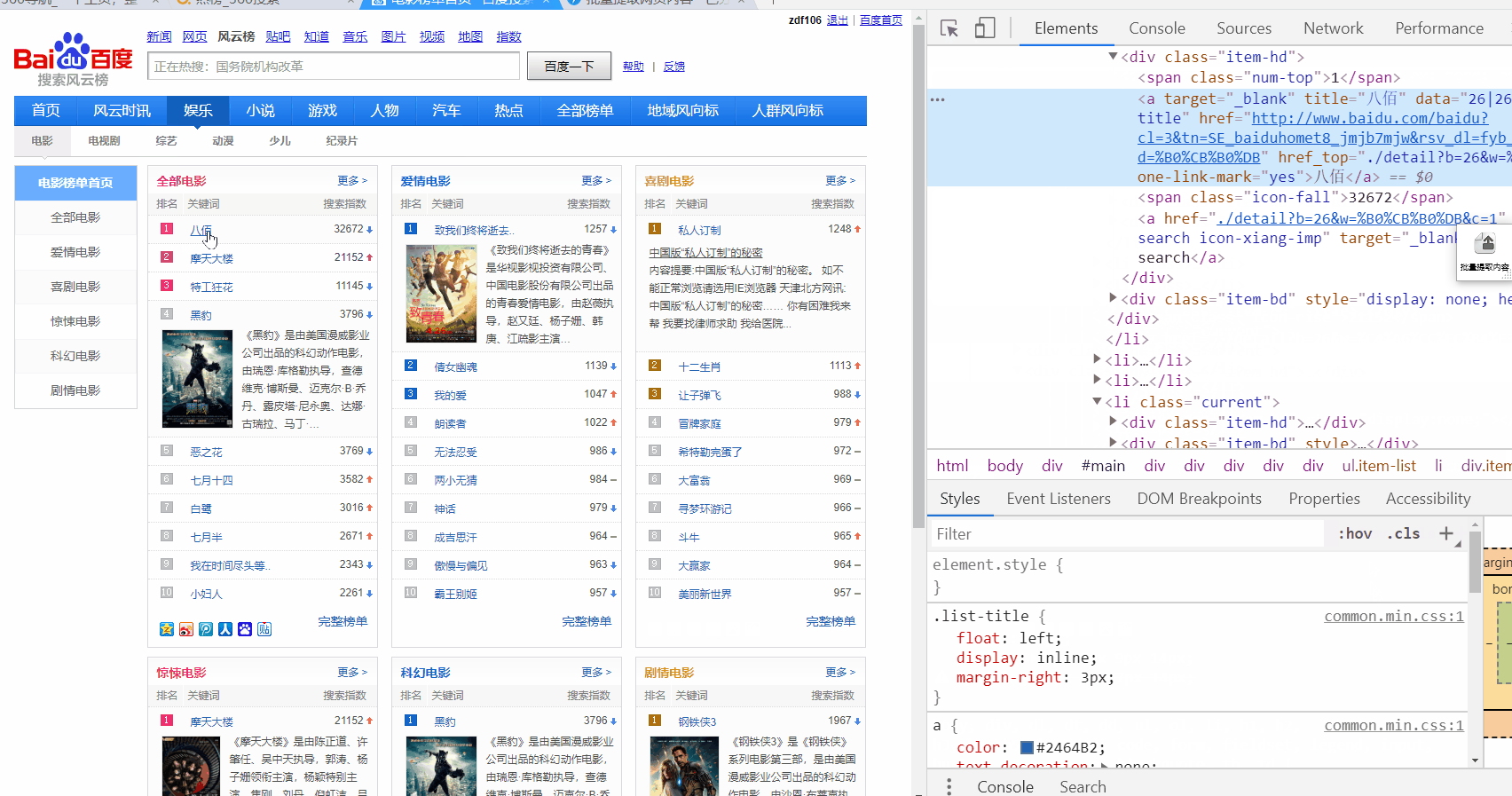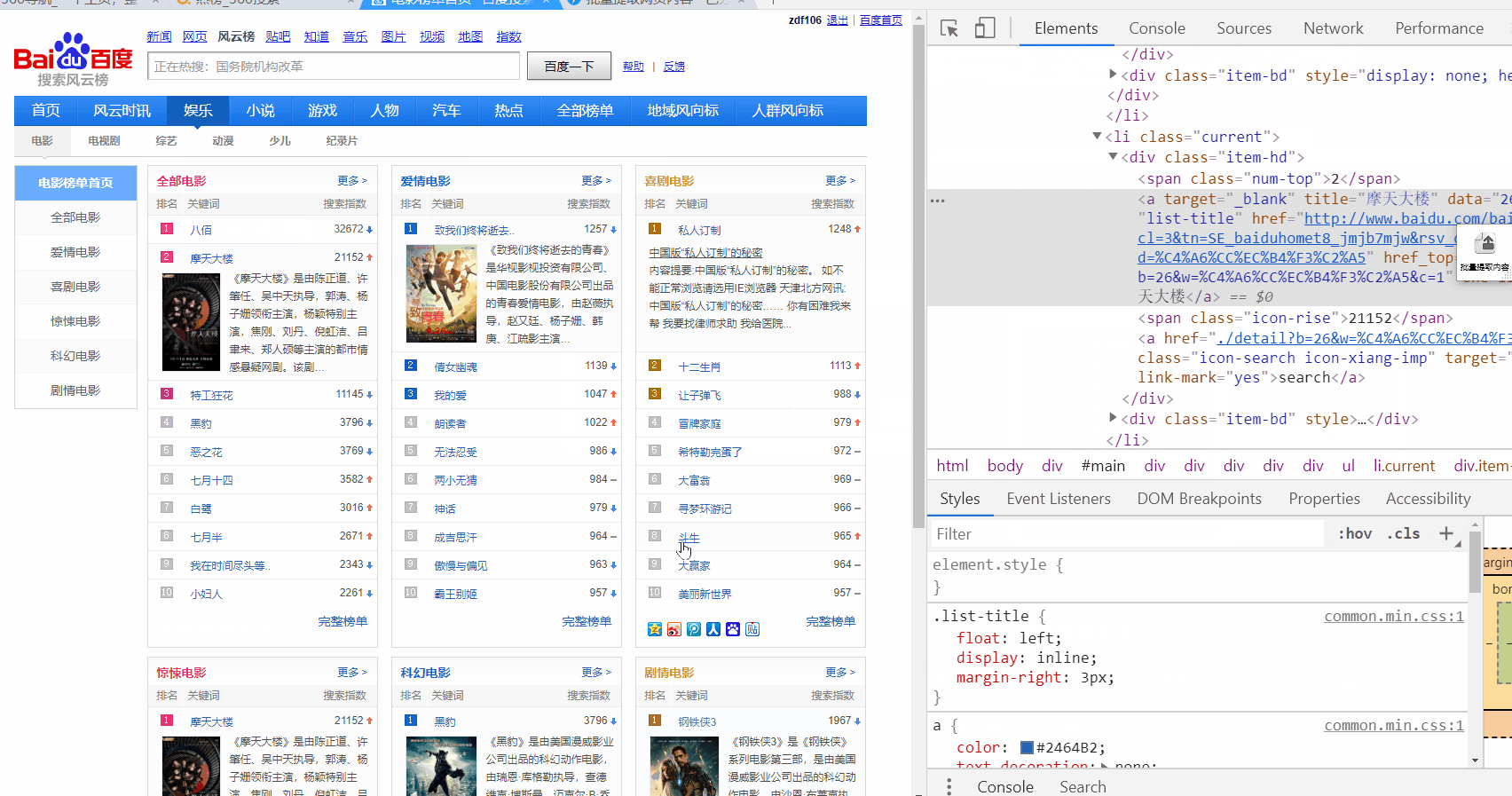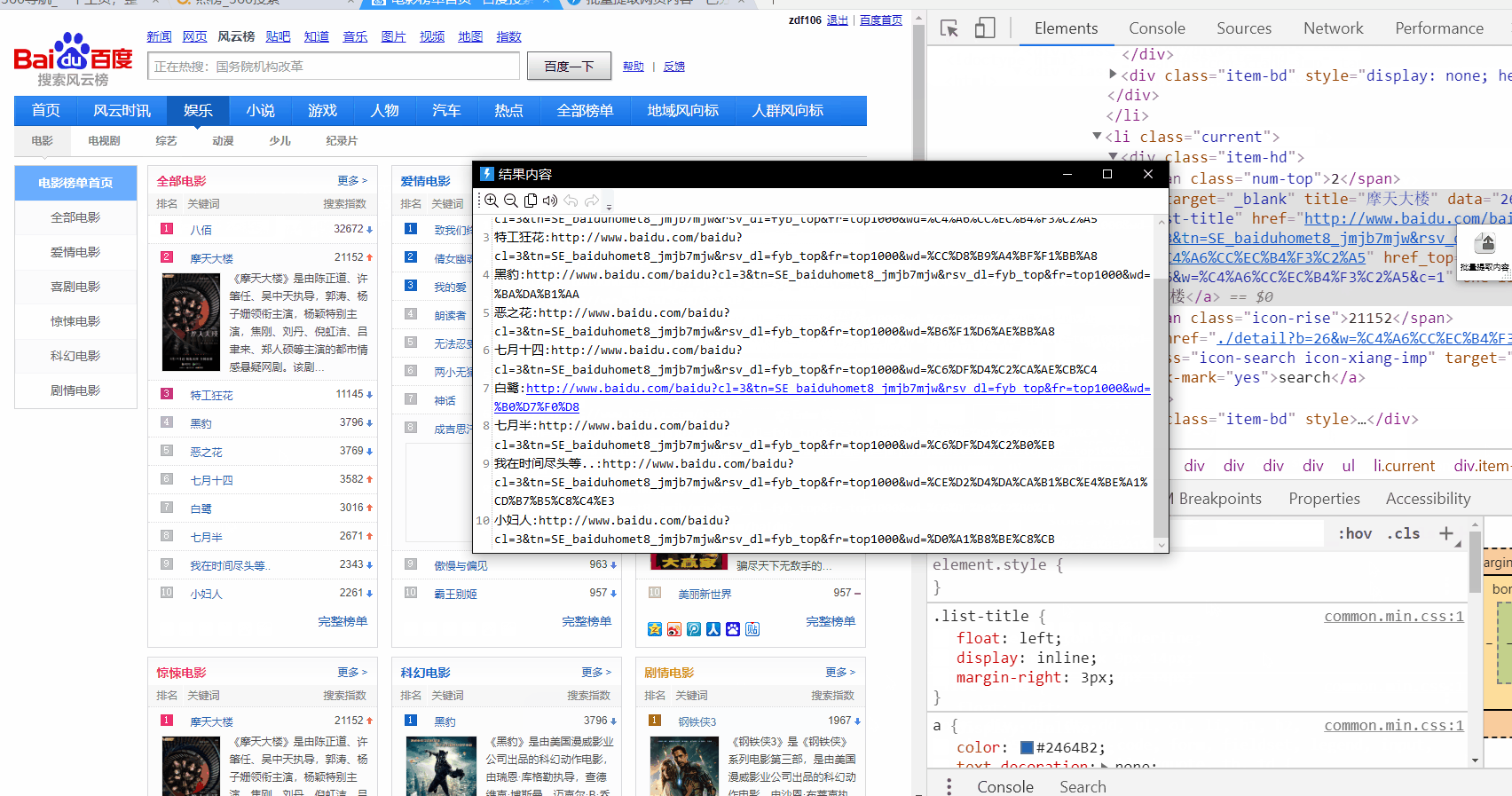
提取多列
自动点击下一页
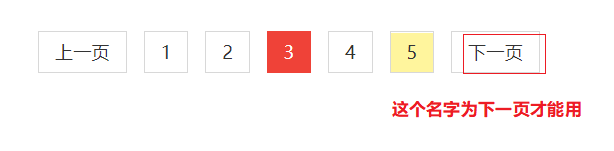
输入自动,使用自带的下一页xpath(基于下一页制作)
下一页的名字为 "下一页" 才能定位成功

手动输入:
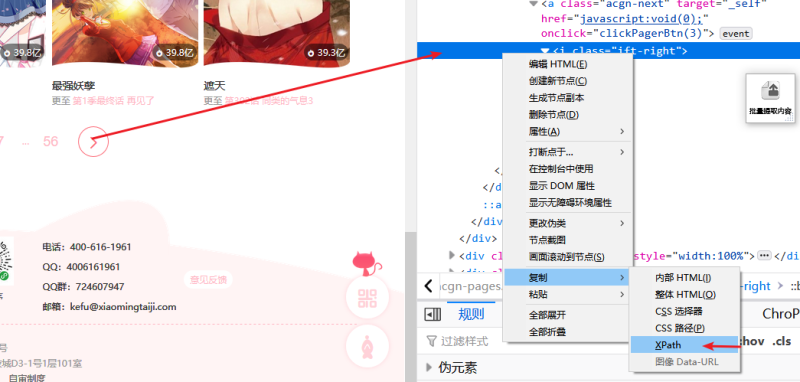
>下页< 这种xapth是 
xpath://a[contains(text(),'下一页')]
title="下一页",这种xpath是
xpath://a[contains(@title,'下一页')]

如果是其他字直接替换就好了,注意比如">",可能是图片生成的,还有就是有些是>加空格,去源码直接复制就好了
xpath://a[contains(text(),'下一页>')]

实在没办法就只能这样,这样可能最后几页提取时可能会跳

最近更新
| 修订版本 | 更新时间 | 更新说明 |
|---|---|---|
| 6 | 2020-09-14 18:36 |
修复bug,增加自动点击下一页
|
| 5 | 2020-09-11 22:23 | 修复bug |
| 4 | 2020-09-09 15:52 | 记录上一次的xpath 方便多次提取 自动模式下 今日手动提取也会显示上次的xpath |

 京公网安备 11010502053266号
京公网安备 11010502053266号