万能识别

适用于
分类(旧)
OCR AI关键词
用户kvgWu0h4BAA
①沏隨緣
用户L15IB-q5BAA
兰台leo
人言可魏
等
6 人赞了这个动作
。
更多信息
| 分享时间 | 2024-10-31 15:53 |
| 最后更新 | 2025-06-06 18:04 |
| 修订版本 | 4 |
| 用户许可 | 可自己使用或修改,不可再分享 |
| Quicker版本 | 1.44.10 |
| 动作大小 | 78 KB |
「AI大模型加持下的「免费」高级OCR工具」
简介
❗「万物」一键OCR为完美格式的Markdown文本
❗免费!没有套路!真免费!
❗正确率嘎嘎高,调用大语言模型
太长不看版
这是一款能将图片内容(包括文字、表格、数学公式等)精准识别并转换为Markdown格式的动作,彻底解决传统OCR(文字识别)造成的排版混乱、复杂内容识别不准的问题。
只需要输入API Key(智谱API完全免费,通义、混元大模型注册可以领取大量免费Tokens),即可实现复杂的OCR功能。【一般场景下,免费的智谱API即可满足要求;超级复杂场景可用其他两个模型!】
纯做公益,欢迎给俺点赞!希望能帮到大家!
功能详介
- 万能识别:本动作支持识别图片中的一切信息,包括文字、结构化文字、图片、表格、混合信息(比如文字+表格)。识别结果将最大程度保留图片中的文字信息、格式信息、排版信息、文字样式信息等,可直接复制为Markdown格式。与传统OCR助手相比,具有以下优势:
- 充分保留排版、格式、文字样式等信息,极大节省时间;
- 得益于多模态大模型的加持,准确精度更高;
- 无需复杂设置,一键「万能识别」,在混合信息场景(如文字+表格、文字+公式等)、复杂表格场景下,依然表现优异;
- 大模型支持:本动作通过调用智谱、通义千问、混元三个多模态大模型的API实现图片识别,可自行切换。只需填写API Key,即可实现「万能识别」。(智谱大模型填写API即可免费使用,让我们一起感谢智谱😭,通义、混元大模型注册可以领取免费Tokens)根据测试,模型AP优劣见下表:
- API Key填写窗口会在第一次使用时弹出,填写正确的API Key,后续可直接使用;
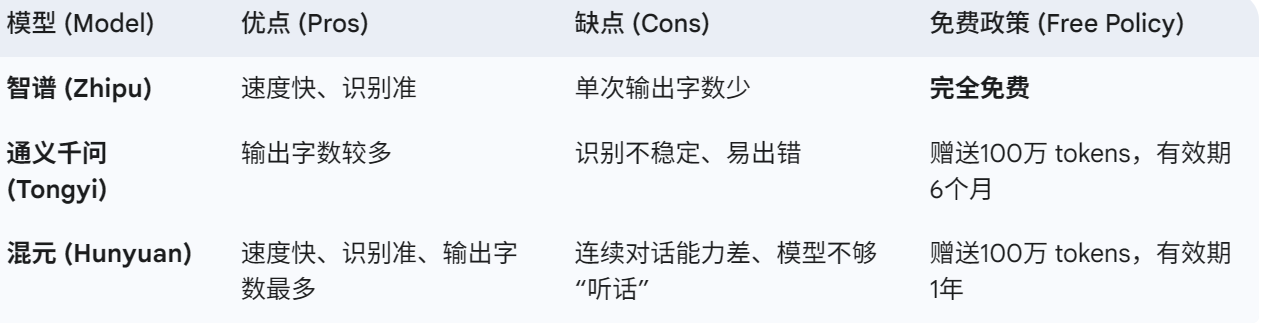
- 太长不看版:一般场景下,免费的智谱API即可满足要求;超级复杂场景可用其他两个模型。
- 两次输出:支持两次输出,如果大模型第一次输出不完整,可支持再次输出,并最终输出格式一致的完整识别结果。
使用手册(文字教程)
- 输入和输出说明:
- 输入:截图,点击动作后,会蹦出截图窗口,截图内容将发送给大模型;
- 输出:模型识别完成后,会自动弹出结果预览窗口,Markdown格式的文本直接复制到剪贴板中。如果设置了「继续输出」,则会蹦出是否继续输出弹窗,点击「是」,模型则会继续输出,并最终弹出完整内容。
- 设置:
- 右键动作,点击「模型选择」,则可以切换大模型,最好只选择一个,默认选择为智谱大模型;
- 右键动作,点击「Prompt」,可自行设定发送给大模型的Prompt;
- 右键动作,点击「继续输出」,勾选后则会在第一次输出完成后蹦出是否继续输出窗口;
- 使用示例
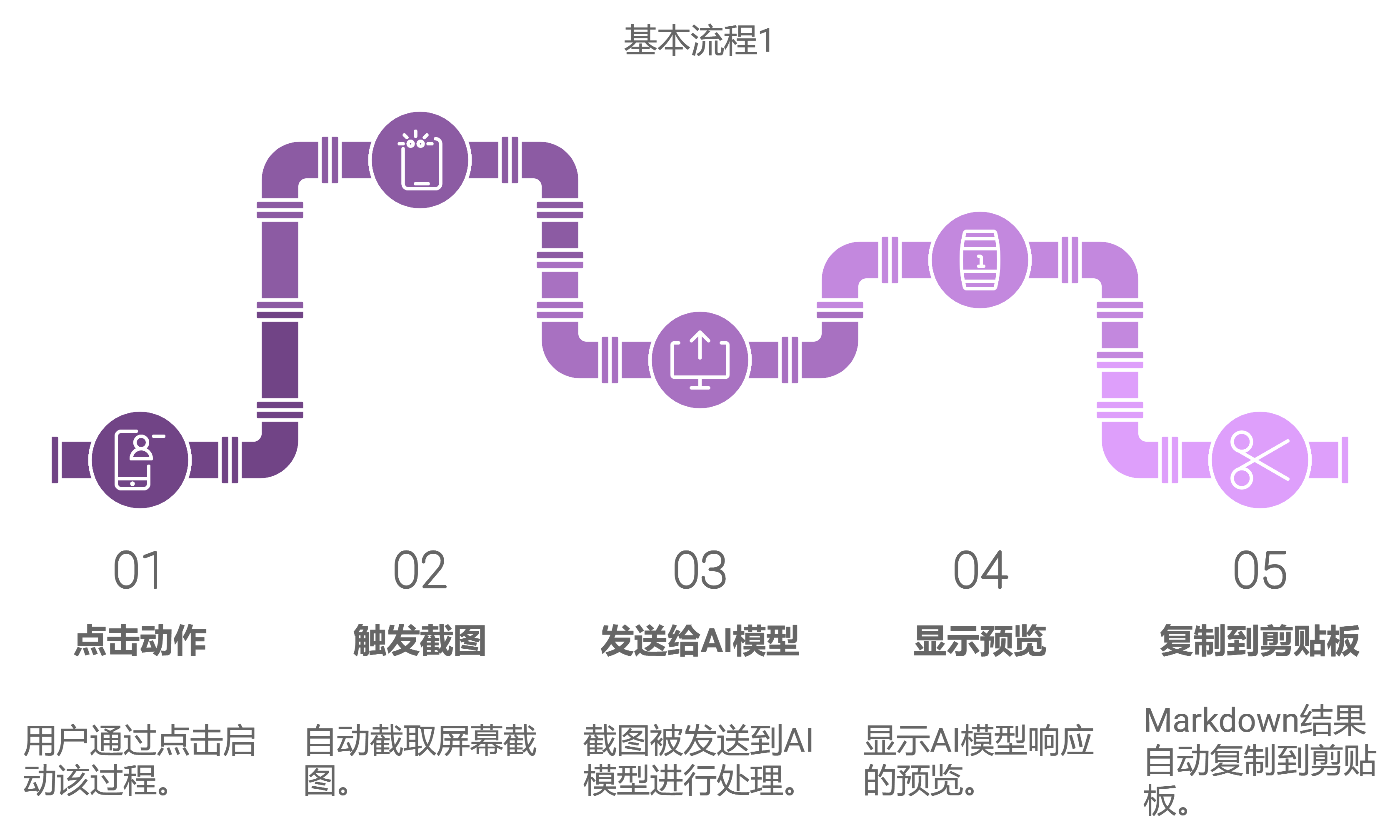
- -未开启「继续输出」功能:点击动作—》触发截图—》截图完成后发送给AI大模型—》蹦出大模型回复预览弹窗—》Markdown结果自动复制到剪贴板;
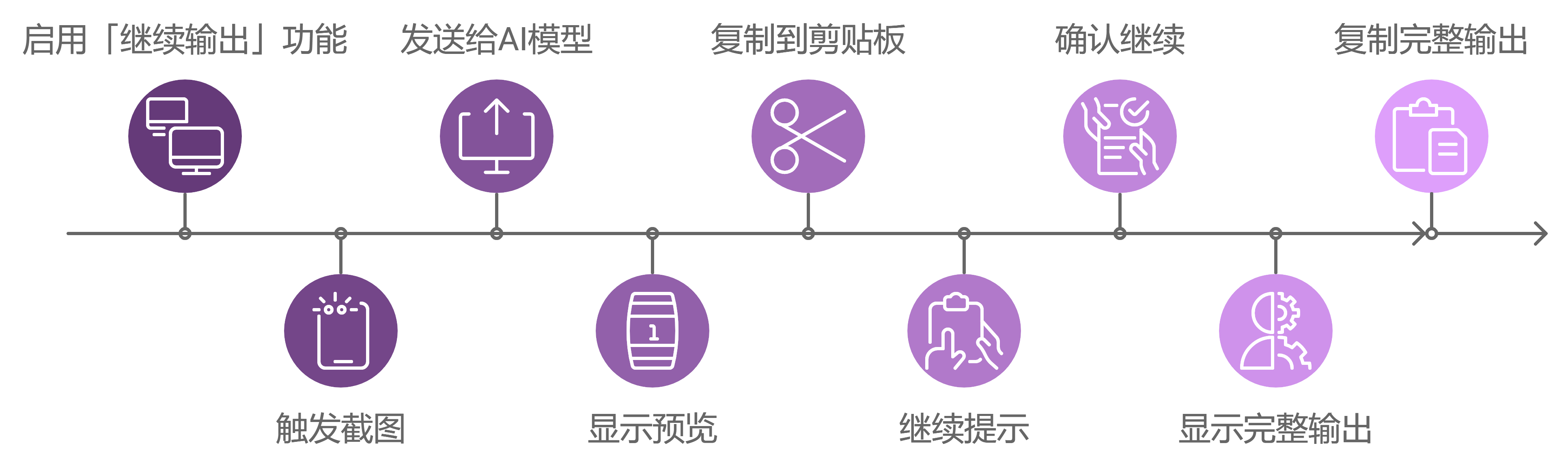
- 开启「继续输出」功能:点击动作—》触发截图—》截图完成后发送给AI大模型—》蹦出大模型回复预览弹窗—》Markdown结果自动复制到剪贴板—》蹦出是否继续输出弹窗—》点击是—》蹦出大模型再次输出后的全部输出弹窗(自动合并),并自动复制到剪贴板。
- 视频教程:「万能识别」- Quicker动作教程_哔哩哔哩_bilibili
欢迎使用~~
作者所声明的动作特征:
- 依赖第三在线服务
- 含有上传数据到网络的功能
最近更新
| 修订版本 | 更新时间 | 更新说明 |
|---|---|---|
| 4 | 2025-06-06 18:04 |
- 更新至最新大模型;
- 识别长度大幅增加,最高可支持8k输出(通义、混元大模型) |
| 3 | 2025-06-05 16:27 | 智谱大模型更新至免费模型(GLM-4V-Flash) |
| 2 | 2025-06-05 15:44 | 混元多模态模型更新至hunyuan-turbos-vision-2025-05-23 |
最近讨论
随便聊聊
· 182
冷眼看世界
2026-02-26 16:43
SUPERSWEET
2026-03-30 16:40
功能建议
· 238
用户L15IB-q5BAA
2025-11-04 21:32
使用问题
· 281
haoqiu
2025-08-27 19:22

 京公网安备 11010502053266号
京公网安备 11010502053266号